[Job] Staff Associate II (Computational Structural Biology) at Columbia University
The X3DNA-DSSR resource is at the forefront of structural bioinformatics, developing advanced tools for analyzing and modeling nucleic acid structures. We are seeking a highly motivated Staff Associate II to join our team and contribute to our next-generation analysis and visualization engine.
To see our resource in action, please visit wDSSR, our new web interface for dissecting and modeling 3D nucleic acid structures: https://web.x3dna-dssr.org/.
We are looking for a candidate with a strong scientific background in structural biology or bioinformatics and a desire to contribute to peer-reviewed publications through community-driven data analysis. We value individuals who are eager to learn, adapt to new technical challenges, and support the global research community.
For the full job description and to submit your application, please visit the official Columbia University posting:
https://apply.interfolio.com/183705
Announcing wDSSR: The Next-Generation Web Interface to X3DNA-DSSR
Dear 3DNA/DSSR Community,
We are thrilled to announce the official launch of wDSSR (https://web.x3dna-dssr.org/), the powerful new web interface to the X3DNA-DSSR analytical engine.
Developed by Drs. Shuxiang Li and Xiang-Jun Lu and supported by NIH grant R24GM153869, wDSSR represents a major leap forward from our highly popular 2019 Web 3DNA 2.0 framework. While Web 3DNA 2.0 has faithfully served the community for the analysis, visualization, and modeling of 3D nucleic acid structures, wDSSR was built from the ground up to take full advantage of modern web technologies and the latest DSSR backend capabilities.
A Modern, Streamlined Scientific Workflow
We have completely overhauled the user interface to provide a clean, intuitive, and task-driven experience. The core modeling and analysis tools are now seamlessly organized into a logical, single-word scientific workflow: Analyze, Rebuild, Model, Circularize, Mutate, Assemble, and Visualize.
Spotlight Feature: The "Assemble" Module
One of the most exciting upgrades is the newly renamed Assemble tab (formerly "Composite"). This advanced composite model builder allows you to effortlessly construct complex, higher-order models by linking any combination of nucleic acid duplexes or protein-DNA/RNA complexes. You can quickly connect up to six distinct target structures, ranging from simple linked A-DNA and B-DNA duplexes to large, protein-decorated structural assemblies.
Immediate Global Adoption
Although wDSSR has just launched, we are incredibly humbled to share that it is already seeing rapid worldwide adoption! According to recent network infrastructure data, the new interface is actively being used by researchers across North America, South America, Europe, and Asia. Within just a few days, we have recorded active sessions from prestigious institutions around the globe, including:
- The Weizmann Institute of Science in Israel
- Katholieke Universiteit Leuven in Belgium
- Queen's University in Canada
- Universidad Nacional Autonoma de Mexico (UNAM) in Mexico
- Emory University and the Wadsworth Centers Laboratories and Research in the United States
- Jawaharlal Nehru University and the China Education and Research Network in Asia
How to Cite
While a dedicated paper for wDSSR is currently in preparation, researchers should cite the server using its URL (https://web.x3dna-dssr.org/) alongside the 2019 Web 3DNA 2.0 paper and the foundational 2015 DSSR paper. Full details and funding acknowledgements can be found on our newly consolidated About page.
We invite you all to try out the new wDSSR platform! As always, your feedback is invaluable to us, and we encourage you to share your thoughts, questions, and structural models via the newly updated Questions & Feedback link in the wDSSR footer.
Happy modeling!
In the field of nucleic acid structures, especially in the ‘RNA world’, we often hear named base pairs (bp). Among those, the Watson-Crick (WC) A–U and G–C bps (see figure below) are by far the most common.

Closely related to the WC bps are the so-called reversed WC (rWC) bps, where the relative glycosidic bond are reversed; instead of being on the same side of the bases as in WC bps shown above, they are now on opposite sides in rWC bps as shown below. According to the Leontis-Westhof (LW) bp classification scheme, the rWC bps belong to trans WC/WC. Following Saenger’s numbering, the rWC A+U bp corresponds to XXI, and the rWC G+C bp XXII.
In the figures below, the name of each type of bp and its LW & Saenger designations (separated by ‘;’) are noted under the corresponding image. All images are generated with 3DNA; for easy comparison, each bp is oriented in the reference frame of the leading base.
 |
 |
| Reversed WC A+U pair |
Reversed WC G+C pair |
| trans WC/WC; XXI |
trans WC/WC; XXII |
The next most famous one is the Hoogsteen A+U bp, which also has a reverse variant, i.e., the rHoogsteen A–U bp (see figure below). Now the major groove edge of A, termed the Hoogsteen edge by LW, is used for pairing with U.
 |
 |
| Hoogsteen A+U pair |
Reversed Hoogsteen A–U pair |
| cis Hoogsteen/WC; XXIII |
trans Hoogsteen/WC; XXIV |
First proposed by Crick in 1966 to account for the degeneracy in codon–anticodon pairing, the Wobble bp is an essential component (in addition to the WC bps) in forming double helical RNA secondary structures.
 |
| Wobble G–U pair |
| cis WC/WC; XXVIII |
The sheared G–A base pair
Sheared G–A is a commonly found non-WC bp in both DNA and RNA structures. Noticeably, tandem sheared G–A bps introduce distinct stacking geometry. Here G uses its minor groove edge, termed the sugar edge by LW, to pair with the Hoogsteen edge of A.
 |
| Sheared G–A pair |
| trans Suger/Hoogsteen; XI |
Dinucleotide platforms
Dinucleotide platforms are formed via side-by-side pairing of adjacent bases; the most common of which are GpU and ApA. Here the sugar (minor-groove) edge of the 5′ base interacts with the Hoogsteen (major-groove) edge of the 3′ base. Since there is only one base-base H-bond in dinucleotide platforms, no Saenger classification is available. In 3DNA output, the GpU dinucleotide platform is designated as G+U, and ApA as A+A.
 |
 |
| GpU dinucleotide platform |
ApA dinucleotide platform |
| cis Sugar/Hoogsteen; n/a |
cis Sugar/Hoogsteen; n/a |
Other named base pairs
There exist other named bps in RNA literature, e.g., G⋅A imino, A⋅C reverse Hoogsteen, G⋅U reverse Wobble etc. In the my experience, they are (much) less commonly used than the ones illustrated above.

From v1.5 or even earlier on, 3DNA provides an automatic classification of a dinucleotide step into A-, B- or TA-DNA conformation. Figure 5 of the 2003 3DNA Nucleic Acids Research paper (NAR03) shows three sets of scatter plots — helical inclination and x‐displacement, dimer step Roll and Slide, and the projected phosphorus z coordinates Zp and Zp(h) — to differentiate the A-, B- and TA-DNA dinucleotide steps.

Among the criteria tested, the most discriminative ones are the projected phosphorus z coordinates, Zp in the middle step frame (see figure below), and Zp(h) defined similarly but in the middle helical frame.

Over the years, I have received many questions regarding the datasets used in generating Figure 5 of NAR03. Back in August 2006, a user asked for IDs of the TA-DNA structures — see DNA standards/statistics using 3DNA. In April 2007, another user requested the same TA-DNA dataset. Early this year, a user asked for 3DNA’s A-DNA definition. More recently, yet another user would like to ask about the DNA set used for the analysis that is presented in Fig 5. in the NAR 2003 paper.
I am glad to see that after nearly a decade of the NAR03 publication, the user community is still interested in knowing details in the work. So I decided to dig into my archive for the original data files and scripts used to generate Figure 5 of NAR03. It was not an easy journey; just releasing the data files and scripts is not enough, I’d like to verify that they work together as intended in today’s computing environment. Luckily, I am finally able to get to the bottom of the issues. The details are in the post Datasets and scripts for reproducing Figure 5 of the 3DNA NAR03 paper. The tarball file named 3DNA-NAR03-Fig5.tar.gz is available by clicking the link.
As noted in post Rectangular block expressed in MDL molfile format, I added the -mol option (in v2.1) to convert 3DNA’s native alchemy to the better-supported MDL molfile format, to make the characteristic schematic representations more widely accessible. Along the line, I have recently further augmented alc2img with the -pdb option to transform alchemy to the PDB format.
While the macromolecular PDB format is certainly not convenient for specifying linkage details of small molecules, it’s nevertheless the best-documented and by far the most widely supported than molfile or alchemy in currently available molecular viewers. For example, the PDB format is consistently supported in Jmol, PyMOL, RasMol, DeepView, and UCSF Chimera. Moreover, the PDB format does have the CONECT section to provide information on atomic connectivity:
The CONECT records specify connectivity between atoms for which coordinates are supplied. The connectivity is described using the atom serial number as shown in the entry. CONECT records are mandatory for HET groups (excluding water) and for other bonds not specified in the standard residue connectivity table.
The alc2img -pdb option takes advantage of the CONECT records and specifies all ‘bond’ linkages explicitly. The usage is very simple — take the standard base-pair rectangular block file (‘Block_BP.alc’) as an example, the conversion can be performed as below:
alc2img -pdb Block_BP.alc Block_BP.pdb
Content of ‘Block_BP.alc’
12 ATOMS, 12 BONDS
1 N -2.2500 5.0000 0.2500
2 N -2.2500 -5.0000 0.2500
3 N -2.2500 -5.0000 -0.2500
4 N -2.2500 5.0000 -0.2500
5 C 2.2500 5.0000 0.2500
6 C 2.2500 -5.0000 0.2500
7 C 2.2500 -5.0000 -0.2500
8 C 2.2500 5.0000 -0.2500
9 C -2.2500 5.0000 0.2500
10 C -2.2500 -5.0000 0.2500
11 C -2.2500 -5.0000 -0.2500
12 C -2.2500 5.0000 -0.2500
1 1 2
2 2 3
3 3 4
4 4 1
5 5 6
6 6 7
7 7 8
8 5 8
9 9 5
10 10 6
11 11 7
12 12 8
Content of ‘Block_BP.pdb’
REMARK 3DNA v2.1 (c) 2012 Dr. Xiang-Jun Lu (http://x3dna.org)
HETATM 1 N ALC A 1 -2.250 5.000 0.250 1.00 1.00 N
HETATM 2 N ALC A 1 -2.250 -5.000 0.250 1.00 1.00 N
HETATM 3 N ALC A 1 -2.250 -5.000 -0.250 1.00 1.00 N
HETATM 4 N ALC A 1 -2.250 5.000 -0.250 1.00 1.00 N
HETATM 5 C ALC A 1 2.250 5.000 0.250 1.00 1.00 C
HETATM 6 C ALC A 1 2.250 -5.000 0.250 1.00 1.00 C
HETATM 7 C ALC A 1 2.250 -5.000 -0.250 1.00 1.00 C
HETATM 8 C ALC A 1 2.250 5.000 -0.250 1.00 1.00 C
HETATM 9 C ALC A 1 -2.250 5.000 0.250 1.00 1.00 C
HETATM 10 C ALC A 1 -2.250 -5.000 0.250 1.00 1.00 C
HETATM 11 C ALC A 1 -2.250 -5.000 -0.250 1.00 1.00 C
HETATM 12 C ALC A 1 -2.250 5.000 -0.250 1.00 1.00 C
CONECT 1 2 4
CONECT 2 1 3
CONECT 3 2 4
CONECT 4 1 3
CONECT 5 6 8 9
CONECT 6 5 7 10
CONECT 7 6 8 11
CONECT 8 5 7 12
CONECT 9 5
CONECT 10 6
CONECT 11 7
CONECT 12 8
END
Ever since the 2003 publication of the initial 3DNA Nucleic Acids Research paper (NAR03), the schematic diagrams of base-pair parameters (see figure below) has become quite popular. Over the years, we have received numerous requests for permission to use the figure, or a portion thereof; as an example, the figure has been adopted into a structural biology textbook. In the 2008 3DNA Nature Protocols paper (NP08), we devoted the very first protocol to “create a schematic image for propeller of 45°”.

Figure legend taken from Figure 1 of NAR03: Pictorial definitions of rigid body parameters used to describe the geometry of complementary (or non‐complementary) base pairs and sequential base pair steps (19). The base pair reference frame (lower left) is constructed such that the x‐axis points away from the (shaded) minor groove edge of a base or base pair and the y‐axis points toward the sequence strand (I). The relative position and orientation of successive base pair planes are described with respect to both a dimer reference frame (upper right) and a local helical frame (lower right). Images illustrate positive values of the designated parameters. For illustration purposes, helical twist (Ωh) is the same as Twist (ω), formerly denoted by Ω (19,20) and helical rise (h) is the same as Rise (Dz).
I recall spending around two weeks to produce the above figure. Content-wise, the figure was constructed in only a short while; it was the little details that took me most of the time.
Over time, I’ve witnessed numerous versions of such schematic images in publications related to DNA/RNA structures. While looking similar, the schematics differ subtly in the magnitude, orientation and relative scale of illustrated parameters. To the best of my knowledge, only 3DNA provides a pragmatic approach to generate the base-pair schematic diagrams consistently.
To make the schematics more readily accessible, I’ve reproduced a high resolution image (in png format) for each of the 14 parameters shown above. You are welcome to pick and match the diagrams as necessary. If you use any of them in your publications, please cite the 3DNA NAR03 and/or NP08 paper(s).
Note that in the schematic diagrams below, the shaded edge (facing the viewer) denotes the minor-groove side of a base or base pair.
| Shear (Sx) |
Stretch (Sy) |
Stagger (Sz) |
 |
 |
 |
| Buckle (κ) |
Propeller (π) |
Opening (σ) |
 |
 |
 |
| Shift (Dx) |
Slide (Dy) |
Rise (Dz) |
 |
 |
 |
| Tilt (τ) |
Roll (ρ) |
Twist (ω) |
 |
 |
 |
| x-displacement (dx) |
y-displacement (dy) |
Helical Rise (h) |
 |
 |
As for Rise above
(for illustration purpose) |
| Inclination (η) |
Tip (θ) |
Helical Twist (Ωh) |
 |
 |
As for Twist above
(for illustration purpose) |
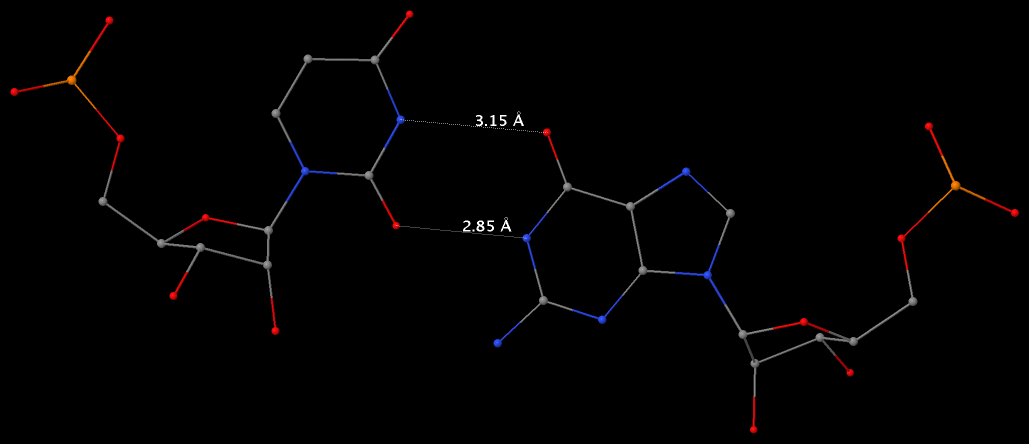
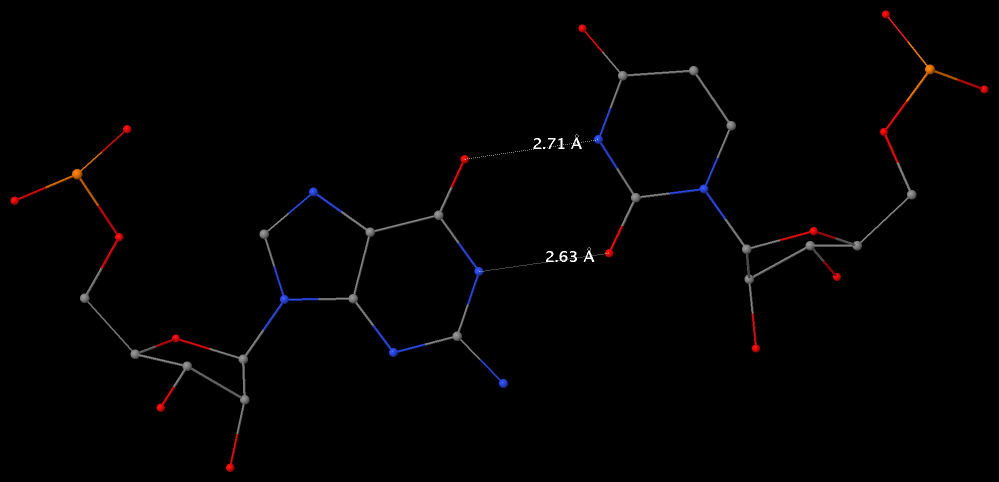
Among the findings of our 2010 Nucleic Acids Research (NAR) article titled The RNA backbone plays a crucial role in mediating the intrinsic stability of the GpU dinucleotide platform and the GpUpA/GpA miniduplex, the key is identifying the O2′(G)…O2P(U) H-bond (see figure below). As noted in a previous post What’s special about the GpU dinucleotide platform?, it was an accidental observation while I was preparing a figure for our 2008 3DNA Nature Protocols paper. Trained as a chemist, after scrutinizing the many occurrances of the GpU platforms in the large ribosomal subunit of Haloarcula marismortui (PDB entry 1jj2), I had no doubt that it is an H-bond. Yet, behind the scene, things were never that straightforward: if it is indeed an H-hbond as we’ve claimed, how could it have been missed altogether by the RNA structural biology community?
...O2P(U) H-bond in the sugar–phosphate backbone.")
Anticipating the potential questions that could be raised by the reviewers, we were extremely careful in characterizing the O2′(G)…O2P(U) H-bond:
- It is formed between the hydroxyl group (donor) of G and a non-bridging phosphate oxygen atom (O2P, acceptor) of U.
- The distance between O2′(G) and O2P(U), 2.68 ± 0.14 Å, is perfect for an H-bond.
- I queried the Cambridge Structure Database for hydroxyl-phosphate H-bonds with similar relative geometry and chemical identity. We found a case in the phospholipid lysophosphatidyl-ethanolamine, where this type of H-bond is highlighted in the abstract: The free glycerol hydroxyl group forms an intramolecular hydrogen bond with a phosphate oxygen and thus affects the conformation and orientation of the head group.
- I also performed a survey of potential O2′(i)…O2P(i+1) H-bonds within dinucleotides regardless of platform configuration, and detected 1186 such pairwise interactions within a distance cutoff of 3.3 Å in RNA crystal structures of 2.5 Å or better resolution.
Careful as we were, we still failed to convince reviewer #3 of our manuscript, which was originally submitted to the RNA journal and finally rejected following the second round of review. Here is an excerpt related to the O2′(G)…O2P(U) H-bond from reviewer #3’s comment:
The first main concern is that the “new” H-bond interaction that the authors propose as an explanation for the greater occurrence of GU platforms versus di-nucleotide combinations does not make much sense on a fundamental chemical and stereo-chemical point of view. Unless the whole community of chemists and biochemists agree to redefine what an H-bond is, the fact that the 2’OH (i) atom is at 2.68 Å from the O2P atom cannot be the only criteria for an H-bond. In fact, if the authors are the first to mention this H-bond, it is because none of the scientists working in RNA structural biology would have considered this to be an H-bond interaction at the first place! H-bonds are known to be very directional. The O2’-H bond should be aligned with one of the electron doublets of O2P to be able to form a proper H-bond. Acceptable variation could be 20° to 30° degree with respect of a straight H-bond interaction, not 90°! The unique paper that the authors cite for justifying their claim cannot be used as a reference. If the authors want to justify that the close proximity of the 2’OH(i) and O2P is the important factor that contributes to preference of GU platforms versus other platforms, they should undergo quantum mechanics calculations to demonstrate it.
This review is so critical that I saw no point in arguing with it — I certainly have neither the power to “redefine what an H-bond is” nor the expertise to perform quantum mechanics (QM) calculations to validate the O2′(G)…O2P(U) H-bond or otherwise. What is compelling to me about the GpU story from the very beginning is that once this sugar-phosphate H-bond is acknowledged, every other parts of our NAR paper follow naturally and logically. Leaving the chicken or the egg issue alone, our work provides a novel perspective about GpU platform’s predominance, the formation of the bulged-G or loop-E motif, the evolutionary co-occurrence of GpUpA and GpA in the GpUpA/GpA miniduplex, and the extreme conservation of GpU observed at most 5′-splice sites. Put another way, we connect the dots to form a coherent picture that is easily understandable to biologists and chemists.
Luckily, after being re-submitted to NAR, the paper was quickly accepted for publication and even selected as a featured article! As another nice surprise, shortly after it was available online as an Advance Access paper, I received an email from Jiri Sponer. Thereafter, we collaborated on a follow-up paper titled Understanding the Sequence Preference of Recurrent RNA Building Blocks Using Quantum Chemistry: The Intrastrand RNA Dinucleotide Platform. While not unexpected, the results of the state-of-the-art QM calculations were nevertheless reassuring:
The mixed-pucker sugar–phosphate backbone conformation found in most GpU platforms, in which the 5′-ribose sugar (G) is in the C2′-endo form and the 3′-sugar (U) in the C3′-endo form, is intrinsically more stable than the standard A-RNA backbone arrangement, partially as a result of a favorable O2′···O2P intraplatform interaction. Our results thus validate the hypothesis of Lu et al. (Lu, X.-J.; et al. Nucleic Acids Res. 2010, 38, 4868–4876) that the superior stability of GpU platforms is partially mediated by the strong O2′···O2P hydrogen bond. …… In contrast, we show that the dinucleotide platform is not properly described in the course of atomistic explicit-solvent simulations. Our work also gives methodological insights into QM calculations of experimental RNA backbone geometries. Such calculations are inherently complicated by rather large data and refinement uncertainties in the available RNA experimental structures, which often preclude reliable energy computations.
So, the O2′(G)…O2P(U) H-bond is more than likely to be real; at least some other scientists working in RNA structural biology do share our view.
See also: What’s special about the GpU dinucleotide platform?
While the Watson-Crick (WC) base pairs (bps) are best-known and most abundant in nucleic acid structures (including RNA), the so-called reverse WC bp variants have received little attention. In the well-established Saenger scheme (see figure below), there are 28 possible bps for A, G, U(T), and C in their cononical (keto- and amino-) tautomeric forms and involving at least two H-bonds. The reverse A·T/U and G·C WC pairs are asymmetric, and are numbered XXI and XXII respectively (middle of right-hand side in the figure below).

In 3DNA, the WC bps are of type M–N and listed as A–T and G–C, consistent with the conventional notation. The reverse WC bps, on the other hand, are of type M+N and listed as A+T and G+C; the ‘+’ signifies the parallel z-axes of the two base reference frames, therefore their dot product is positive (see figure 2 in post Hoogsteen and reverse Hoogsteen base pairs).
As of this writing, a Google search of the phrase “reverse Watson Crick base pair” does not come up with anything informative — the top hit is the Jena Library page titled Nucleic Acid Nomenclature and Structure showing the same set of 28 possible bps only with explicit base chemical structures, as compiled by Tinoco Jr. et al. (1993).
However, once I look into this special type of bps, a quick search in PDB entry 1jj2, the Haloarcula marismortui large ribosomal subunit solved at 2.4 Å resolution, revealed nine reverse WC bps as shown below:
__U.U..0.205._ __A.A..0.437._ [U+A]
__C.C..0.1186._ __G.G..0.1190._ [C+G]
__C.C..0.1377._ __G.G..0.1683._ [C+G]
__C.C..0.1856._ __G.G..0.1873._ [C+G]
__A.A..0.2054._ __U.U..0.2648._ [A+U]
__U.U..0.2109._ __A.A..0.2467._ [U+A]
__A.A..0.2301._ __U.U..0.2306._ [A+U]
__A.A..0.2321._ __U.U..0.2378._ [A+U]
__C.C..0.2510._ __G.G..0.2564._ [C+G]
The following figure shows a representative reverse WC A+U bp (0.A437 with 0.U205, top), and a representative reverse WC G+C bp (0.G1683 with 0.C1377, bottom). For easy comparison, the two reverse WC bps are orientated in the reference frames of A and G, respectively.
In future releases of 3DNA, presumably starting from v2.2, we plan to provide a new component to classify bps according to the Saenger scheme, the Leontis/Westhof notation, and the geometric parameter-based strategy. Overall, the three bp classification methods are complementary in functionality, but with increased sophistication and applicability.
The A·U (or A·T) Hoogsteen pair is a well-known type of base pair (bp), named after the scientist who discovered it. As shown in the Figure below (left), in the Hoogsteen bp scheme, adenine uses its N7 (acceptor) and N6 (donor) atoms at the major groove edge to form two H-bonds with the N3 (donor) and O4 (acceptor) atoms from uracil, respectively. Interestingly, if the uracil base ring is flipped around the N7(A)…N3(U) H-bond by 180 degrees, N6(A) now forms an H-bond with O2(U), i.e., N6(A)…O2(U): this pairing scheme is called the reverse Hoogsteen bp (right).

I first knew about the Hoogsteen bp from Saenger’s book titled “Principles of Nucleic Acid Structure”. My knowledge of the Hoogsteen bp deepened as I tried to categorize different types of bps, especially in RNA-containing structures, in a consistent and rigorous computational framework. Thus, in the 3DNA NAR03 publication, we discussed specifically the bp (M+N type) and compared it with the A·U Watson-Crick bp (M–N type), as shown in the Figure below:

Antiparallel and parallel combinations of adenine (A) and uracil (U) base pair ‘faces’: (a) the antiparallel Watson–Crick A–U pair with opposing faces (shaded versus unshaded) and a 1.5 Å Stretch introduced to separate the two base reference frames; (b) the parallel Hoogsteen A+U pair with base pair faces of the same sense. Black dots on bases denote the C1′ atoms on the attached sugars.
However, only recently did I read the two original publications by Hoogsteen:
- The two-page long preliminary report, titled The structure of crystals containing a hydrogen-bonded complex of 1-methylthymine and 9-methyladenine [Acta Cryst. (1959). 12, pp.822-3]. It contains only a single reference, i.e. the 1953 Watson-Crick DNA structure Nature paper. Reading carefully through the two pages, I know why Hoogsteen used the methylated derivatives of thymine and adenine, and how the failed initial interpretation of the experimental “vector-density map” based on the Watson-Crick A-T bp led to the discovery of the new base-pairing scheme:
The fact that the first trial structure could not be refined led to a more critical scrutiny of the generalized projection and a greater emphasis on the significance of certain spurious peaks and on relatively large variations in the heights of peaks that were assumed to represent atoms. The correct structure was finally discovered by changing the positions of a few atoms in the 9-methyladenine portion of the asymmetric unit.
I enjoyed reading these two papers a lot. More generally, I like such focused articles where authors get directly to a point and addressed it thoroughly and clearly.
As a side note, the term Hoogsteen “edge” appears frequently in nowaday’s publications of RNA structures: in the Leontis-Westhof bp classification scheme, this term simply means the major groove edge in what would be a Watson-Crick bp geometry.
3DNA, following SCHNArP, uses the alchemy file format for the schematic base-pair rectangular block representation. Alchemy is a simple molecular file format, suitable for chemical compounds by specifying atom positions and bond linkages explicitly. By checking a sample alchemy file (here for drug aspirin), scientists with chemistry knowledge should have little problem in figuring out what each field means. As it happens, the 3DNA alchemy representation of the base-pair rectangular block is much simpler than that of a typical chemical compound (e.g., aspirin). No different partial atomic charges or atom types, no distinction between single-, double- or aromatic bond types, the base-pair block can be specified with uniform pseudo-atoms (nodes) and pseudo-bonds (edges). Apart from being simple, alchemy was one of the common file formats supported by RasMol — that’s the pragmatic reason why I adopted the format in SCHNArP and 3DNA.
Over the years, 3DNA has been continuously using the alchemy format for base and base-pair rectangular blocks. It forms the basis of the Calladine-Drew style schematic representation images in PostScript (.eps), Xfig (.fig) and Raster3d (.r3d) formats. However, outside 3DNA, the alchemy format is not widely supported by popular molecular graphics programs, including RasMol, Jmol and PyMOL:
- RasMol v2.6.4, from Roger Sayle (the original author of RasMol), is mostly fine, except that the
-noconnect option should be specified. As noted in the 3DNA Nature Protocols (2008) paper, The option ‘-noconnect’ makes sure that RasMol uses only the linkage information specified in the Alchemy file (by setting the CalcBondsFlag to false). … The … Alchemy files [can] contain explicitly specified coordinate axes, which would interfere with the default bond-calculation algorithm in RasMol.
- RasMol v2.7.x has a bug in displaying alchemy files.
- Jmol begins to support the alchemy format as of 11.7.18 (December 2008), following my request [see initial discussion and follow-up].
- PyMOL does not recognize the alchemy format.
To make the schematic base-pair rectangular block representation more broadly accessible, I have recently added the -mol option to alc2img in 3DNA v2.1 to readily convert an alchemy file to the well-documented and widely supported MDL molfile format. The usage is very simple — take the standard base-pair rectangular block file (Block_BP.alc) as an example, the conversion can be performed as below:
alc2img -mol Block_BP.alc Block_BP.mol
alc2img -molv3000 Block_BP.alc Block_BP_v3000.mol
Note the followings:
- By default, the
-mol option converts alchemy to V2000 molfile format. However, if the number of atoms/bonds is greater then 999, the extended V3000 molfile format is used.
- The V3000 molfile format can be explicitly specified with
-molv3000 (or -mol3), as shown above.
- Only V2000 molfile is consistently supported by RasMol, Jmol and PyMOL. On the other hand, while Jmol recognizes V3000 molfile, RasMol and PyMOL do not.
- For reference, the three files — Block_BP.alc, Block_BP.mol, and Block_BP_v3000.mol — are enclosed below.
Content of ‘Block_BP.alc’
12 ATOMS, 12 BONDS
1 N -2.2500 5.0000 0.2500
2 N -2.2500 -5.0000 0.2500
3 N -2.2500 -5.0000 -0.2500
4 N -2.2500 5.0000 -0.2500
5 C 2.2500 5.0000 0.2500
6 C 2.2500 -5.0000 0.2500
7 C 2.2500 -5.0000 -0.2500
8 C 2.2500 5.0000 -0.2500
9 C -2.2500 5.0000 0.2500
10 C -2.2500 -5.0000 0.2500
11 C -2.2500 -5.0000 -0.2500
12 C -2.2500 5.0000 -0.2500
1 1 2
2 2 3
3 3 4
4 4 1
5 5 6
6 6 7
7 7 8
8 5 8
9 9 5
10 10 6
11 11 7
12 12 8
Content of ‘Block_BP.mol’ (V2000)
Block_BP.alc
XL 3DNAv2
Converted from Alchemy format: Thu May 3 23:35:20 2012
12 12 0 0 0 1 V2000
-2.2500 5.0000 0.2500 N 0 0 0 0 0 0 0 0 0 0 0 0
-2.2500 -5.0000 0.2500 N 0 0 0 0 0 0 0 0 0 0 0 0
-2.2500 -5.0000 -0.2500 N 0 0 0 0 0 0 0 0 0 0 0 0
-2.2500 5.0000 -0.2500 N 0 0 0 0 0 0 0 0 0 0 0 0
2.2500 5.0000 0.2500 C 0 0 0 0 0 0 0 0 0 0 0 0
2.2500 -5.0000 0.2500 C 0 0 0 0 0 0 0 0 0 0 0 0
2.2500 -5.0000 -0.2500 C 0 0 0 0 0 0 0 0 0 0 0 0
2.2500 5.0000 -0.2500 C 0 0 0 0 0 0 0 0 0 0 0 0
-2.2500 5.0000 0.2500 C 0 0 0 0 0 0 0 0 0 0 0 0
-2.2500 -5.0000 0.2500 C 0 0 0 0 0 0 0 0 0 0 0 0
-2.2500 -5.0000 -0.2500 C 0 0 0 0 0 0 0 0 0 0 0 0
-2.2500 5.0000 -0.2500 C 0 0 0 0 0 0 0 0 0 0 0 0
1 2 1 0 0 0
2 3 1 0 0 0
3 4 1 0 0 0
4 1 1 0 0 0
5 6 1 0 0 0
6 7 1 0 0 0
7 8 1 0 0 0
5 8 1 0 0 0
9 5 1 0 0 0
10 6 1 0 0 0
11 7 1 0 0 0
12 8 1 0 0 0
M END
Content of ‘Block_BP_v3000.mol’ (V3000)
Block_BP.alc
XL 3DNAv2
Converted from Alchemy format: Thu May 3 23:22:04 2012
0 0 0 0 0 999 V3000
M V30 BEGIN CTAB
M V30 COUNTS 12 12 0 0 0
M V30 BEGIN ATOM
M V30 1 N -2.2500 5.0000 0.2500 0
M V30 2 N -2.2500 -5.0000 0.2500 0
M V30 3 N -2.2500 -5.0000 -0.2500 0
M V30 4 N -2.2500 5.0000 -0.2500 0
M V30 5 C 2.2500 5.0000 0.2500 0
M V30 6 C 2.2500 -5.0000 0.2500 0
M V30 7 C 2.2500 -5.0000 -0.2500 0
M V30 8 C 2.2500 5.0000 -0.2500 0
M V30 9 C -2.2500 5.0000 0.2500 0
M V30 10 C -2.2500 -5.0000 0.2500 0
M V30 11 C -2.2500 -5.0000 -0.2500 0
M V30 12 C -2.2500 5.0000 -0.2500 0
M V30 END ATOM
M V30 BEGIN BOND
M V30 1 1 1 2
M V30 2 1 2 3
M V30 3 1 3 4
M V30 4 1 4 1
M V30 5 1 5 6
M V30 6 1 6 7
M V30 7 1 7 8
M V30 8 1 5 8
M V30 9 1 9 5
M V30 10 1 10 6
M V30 11 1 11 7
M V30 12 1 12 8
M V30 END BOND
M V30 END CTAB
M END
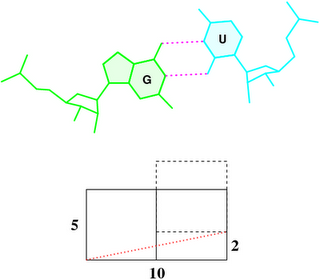
In the standard base reference frame report, a whole section is devoted to the discussion of intrinsic correlations between base-pair and dimer step parameters (see figure below). Among the four sets of associations, the effect of Δbuckle (difference in consecutive base-pair buckles) on rise is most noticeable and easiest to understand. The Δshear vs. twist relationship is similarly significant, due to its close connection to the wobble G–T/G–U pair; yet the concept is less comprehensible, especially to occasional 3DNA users. This post aims to address the issue of how Δshear effects twist.

Under the standard base reference frame used in 3DNA, the wobble base-pair has a ~2.0 Å shear: the displacement is positive for U–G, and negative for G–U [see figure below, examples selected from 5S rRNA (chain 9) U82–G100 and G83–U99 of the Haloarcula marismortui large ribosomal subunit, PDB id: 1jj2].
As noted in the section “treatment of non-Watson–Crick base pairing motifs” of the 3DNA Nucleic Acids Research paper (2003), “Large Shear of the G–U wobble base pair influences the calculated but not the ‘observed’ Twist. The 3DNA numerical values of Twist [of the C7G8·U12G13 and G8C9·G11U12 dimer steps of the Escherichia coli tRNAAsp x-ray crystal structure (PDB id: 485d)], 20° (top) and 43° (bottom), differ from the visualization of nearly equivalent Twist suggested by the angle between successive C1′···C1′ vectors (finely dotted lines).”

To make it clear why that’s the case, the figure below shows a G–U wobble pair in atomic representation (top), and a schematic base pair rectangular block of dimension 10×5 (Å, bottom). A shear of –2 Å moves U upwards, as outlined by the dashed rectangle, and causes a ‘misalignment’ of 11.3° between the C1′···C1′ vector (red dotted line) and the base-centered mean y-axis (horizontal line):
atan2(2, 10) * 180 / pi = 11.3°
To a first order approximation, that is the difference in twist angle. So whenever a wobble pair is next to a normal Watson-Crick pair, there would be a ~11° “observed” discrepancy with 3DNA calculated twist angle. Moreover, when a G–U wobble is next to a U–G wobble pair or vice versa, the difference would be doubled to ~22°.








{kind=link}