Announcing wDSSR: The Next-Generation Web Interface to X3DNA-DSSR
Dear 3DNA/DSSR Community,
We are thrilled to announce the official launch of wDSSR (https://web.x3dna-dssr.org/), the powerful new web interface to the X3DNA-DSSR analytical engine.
Developed by Drs. Shuxiang Li and Xiang-Jun Lu and supported by NIH grant R24GM153869, wDSSR represents a major leap forward from our highly popular 2019 Web 3DNA 2.0 framework. While Web 3DNA 2.0 has faithfully served the community for the analysis, visualization, and modeling of 3D nucleic acid structures, wDSSR was built from the ground up to take full advantage of modern web technologies and the latest DSSR backend capabilities.
A Modern, Streamlined Scientific Workflow
We have completely overhauled the user interface to provide a clean, intuitive, and task-driven experience. The core modeling and analysis tools are now seamlessly organized into a logical, single-word scientific workflow: Analyze, Rebuild, Model, Circularize, Mutate, Assemble, and Visualize.
Spotlight Feature: The "Assemble" Module
One of the most exciting upgrades is the newly renamed Assemble tab (formerly "Composite"). This advanced composite model builder allows you to effortlessly construct complex, higher-order models by linking any combination of nucleic acid duplexes or protein-DNA/RNA complexes. You can quickly connect up to six distinct target structures, ranging from simple linked A-DNA and B-DNA duplexes to large, protein-decorated structural assemblies.
Immediate Global Adoption
Although wDSSR has just launched, we are incredibly humbled to share that it is already seeing rapid worldwide adoption! According to recent network infrastructure data, the new interface is actively being used by researchers across North America, South America, Europe, and Asia. Within just a few days, we have recorded active sessions from prestigious institutions around the globe, including:
- The Weizmann Institute of Science in Israel
- Katholieke Universiteit Leuven in Belgium
- Queen's University in Canada
- Universidad Nacional Autonoma de Mexico (UNAM) in Mexico
- Emory University and the Wadsworth Centers Laboratories and Research in the United States
- Jawaharlal Nehru University and the China Education and Research Network in Asia
How to Cite
While a dedicated paper for wDSSR is currently in preparation, researchers should cite the server using its URL (https://web.x3dna-dssr.org/) alongside the 2019 Web 3DNA 2.0 paper and the foundational 2015 DSSR paper. Full details and funding acknowledgements can be found on our newly consolidated About page.
We invite you all to try out the new wDSSR platform! As always, your feedback is invaluable to us, and we encourage you to share your thoughts, questions, and structural models via the newly updated Questions & Feedback link in the wDSSR footer.
Happy modeling!
Recently, I came across the NAR breakthrough article titled 'Crystal Structure of the Class V GTP-Binding RNA Aptamer Bound to Its Ligand: GTP Recognition by a Topologically Complex Intermolecular G-Quadruplex' by Stafflinger et al. (2025). I read the paper carefully several times and really enjoyed both the content and the writing style. This work offers new insights into the structural complexities and ligand recognition capabilities of RNA. The 1.6-Å high-resolution X-ray crystal structure (PDB id: 9hrf) of the aptamer–GTP complex explains why the class V GTP aptamer has a particularly high affinity and specificity for GTP: The GTP ligand is integrated into one layer of a two-layered G-quadruplex, which is extended on one side by a UUGA tetrad and on the other side by a Watson–Crick base pair (C48–G52) that is stacked by an unpaired adenine (A49). Please see the figure below for further details.

DSSR can readily analyze this complex structure, by simply running the following command:
x3dna-dssr -i=9hrf.pdb --pair-water -o=9hrf.out
The --pair-water option enables the detection of water-mediated base pairs. For instance, it identifies the G41-water-A45 interaction, which is highlighted both below and within the UUGA tetrad shown in the lower left-corner of the figure above.
Base pairs
In total, DSSR identifies 37 base pairs, including:
- A7-G62 imino pair (
A-G Imino 08-VIII cWW cW-W)
- U9+U10 platform (
U+U Platform -- cSH cm+M)
- U9+G41 reverse wobble (
U+G rWobble 27-XXVII tWW tW+W)
- Pseudo-knotted U10-A45 interaction (
U-A WC 20-XX cWW cW-W) along with two G-tetrads forming G12+G46 and G13+G47 pairs (G+G -- 06-VI cHW cM+W)
- U29+G32 in the apical tetra-loop (
U+G -- -- tSW tm+W)
- Water-mediated G41-A45 pairing (
G-A Water -- cHH cM-M)
- Watson-Crick C48-G52 pair (
C-G WC 19-XIX cWW cW-W)
Note how DSSR's automatically derived pair names help orient readers to structural features, particularly stretches of Watson-Crick base pairs forming stems. DSSR categorizes base pairs using the widely accepted Saenger nomenclature and the Leontis-Westhof (LW) scheme. Moreover, it provides 3DNA/DSSR's unique M+N versus M–N distinction, which, along with a set of six parameters, allows for a rigorous characterization of base-pairing geometries.
DSSR also identifies isolated canonical base pairs that do not belong to any stem. In the PDB structure 9hrf, these are U10-A45 and C48-G52 (see below and in the upper-right corner of the figure above).
List of 37 base pairs
nt1 nt2 bp name Saenger LW DSSR
7 A.A7 A.G62 A-G Imino 08-VIII cWW cW-W
9 A.U9 A.U10 U+U Platform -- cSH cm+M
10 A.U9 A.G41 U+G rWobble 27-XXVII tWW tW+W
11 A.U10 A.A45 U-A WC 20-XX cWW cW-W
12 A.G12 A.G46 G+G -- 06-VI cHW cM+W
15 A.G13 A.G47 G+G -- 06-VI cHW cM+W
31 A.U29 A.G32 U+G -- -- tSW tm+W
33 A.G41 A.A45 G-A Water -- cHH cM-M
37 A.C48 A.G52 C-G WC 19-XIX cWW cW-W
Multiplets
DSSR identifies three multiplets, the first two of which are illustrated in the figure above.
List of 3 multiplets
1 nts=4 UUGA A.U9,A.U10,A.G41,A.A45
2 nts=4 GGGg A.G12,A.G42,A.G46,A.GTP100
3 nts=4 GGGG A.G13,A.G40,A.G43,A.G47
Stems, helices, and coaxial stacks
DSSR identifies three stems composed of (6, 8, 7) canonical pairs, each featuring continuous backbones. These three stems are coaxially arranged into a 23-pair-long helix through base-stacking interactions, irrespective of the type of base pair and the backbone connectivity (see below). The two additional base pairs within the 23-pair-long helix are the A7-G62 imino pair and the U29+G32 pair located in the apical tetra-loop. DSSR's geometric approach for identifying stems and helices aligns well with visual inspection, as demonstrated in the upper-left panel of the figure above.
Note: a helix is defined by base-stacking interactions, regardless of bp
type and backbone connectivity, and may contain more than one stem.
helix#number[stems-contained] bps=number-of-base-pairs in the helix
bp-type: '|' for a canonical WC/wobble pair, '.' otherwise
helix-form: classification of a dinucleotide step comprising the bp
above the given designation and the bp that follows it. Types
include 'A', 'B' or 'Z' for the common A-, B- and Z-form helices,
'.' for an unclassified step, and 'x' for a step without a
continuous backbone.
--------------------------------------------------------------------
helix#1[3] bps=23
strand-1 5'-GGGCGCAUAGGUCGGUCGCUGCU-3'
bp-type ||||||.|||||||||||||||.
strand-2 3'-CCCGUGGAUCCGGUCAGUGACGG-5'
helix-form AAA..AxAAA....xA..AAA.
1 A.G1 A.C68 G-C WC 19-XIX cWW cW-W
2 A.G2 A.C67 G-C WC 19-XIX cWW cW-W
3 A.G3 A.C66 G-C WC 19-XIX cWW cW-W
4 A.C4 A.G65 C-G WC 19-XIX cWW cW-W
5 A.G5 A.U64 G-U Wobble 28-XXVIII cWW cW-W
6 A.C6 A.G63 C-G WC 19-XIX cWW cW-W
7 A.A7 A.G62 A-G Imino 08-VIII cWW cW-W
8 A.U14 A.A60 U-A WC 20-XX cWW cW-W
9 A.A15 A.U59 A-U WC 20-XX cWW cW-W
10 A.G16 A.C58 G-C WC 19-XIX cWW cW-W
11 A.G17 A.C57 G-C WC 19-XIX cWW cW-W
12 A.U18 A.G56 U-G Wobble 28-XXVIII cWW cW-W
13 A.C19 A.G55 C-G WC 19-XIX cWW cW-W
14 A.G20 A.U54 G-U Wobble 28-XXVIII cWW cW-W
15 A.G21 A.C53 G-C WC 19-XIX cWW cW-W
16 A.U22 A.A39 U-A WC 20-XX cWW cW-W
17 A.C23 A.G38 C-G WC 19-XIX cWW cW-W
18 A.G24 A.U37 G-U Wobble 28-XXVIII cWW cW-W
19 A.C25 A.G36 C-G WC 19-XIX cWW cW-W
20 A.U26 A.A35 U-A WC 20-XX cWW cW-W
21 A.G27 A.C34 G-C WC 19-XIX cWW cW-W
22 A.C28 A.G33 C-G WC 19-XIX cWW cW-W
23 A.U29 A.G32 U+G -- -- tSW tm+W
List of 1 coaxial stack
1 Helix#1 contains 3 stems: [#1,#2,#3]
Loops
DSSR identifies two hairpin loops, one internal loop, and a [0,8,0] 3-way junction loop by default. As shown in the secondary structure depicted in the upper-left corner of the figure above, these results are evident. When excluding the two isolated canonical base pairs from consideration of secondary structures, DSSR identifies one hairpin loop composed of four nucleotides (U29 to G32), a bulge made up of thirteen nucleotides (G40 to G52), and an internal loop consisting of seven nucleotides on one strand (A7 to G13) and two nucleotides on the other strand (G61 and G62), precisely as described in the Stafflinger et al. (2025) paper.
The literature is inconsistent in its treatment of isolated canonical base pairs within RNA secondary structures. For instance, as detailed in the DSSR User Manual (Figure 3B), considering the isolated WC C−G pair (between C2658 and G2663) reveals the reported GUAA tetraloop (Correll et al., 2003) in PDB entry 1msy and a [5,4] asymmetric internal loop. Without this consideration, the tetraloop and internal loop delineated by the C−G pair merge, resulting in an enlarged hairpin loop spanning 17 nucleotides (from C2652 to G2668).
G-quadruplex
In the class V GTP aptamer-GTP complex structure (PDB entry: 9hrf), the two G-tetrads are formed by guanine nucleotides originating from two loop regions separated by an eight-base-pair A-form stem. This arrangement results in a complex and previously unobserved G-quadruplex topology. DSSR easily identifies the two G-tetrads that form a G4-helix (but not a G4-stem), which is defined by stacking interactions of G4-tetrads, regardless of backbone connectivity. In principle, a G4-helix may include more than one G4-stem via coaxial stacking interactions. The G4 helix/stem are defined in a similar manner to the double-stranded helix/stem as described above.
The relevant DSSR output is provided below. Observe the varying glycosidic bond patterns and groove dimensions, along with two non-G4-stem loops that include two terminal guanosines, which align with Figure 2B of Stafflinger et al. (2025).
List of 1 G4-helix
Note: a G4-helix is defined by stacking interactions of G4-tetrads, regardless
of backbone connectivity, and may contain more than one G4-stem.
helix#1[0] layers=2 INTRA-molecular
1 glyco-bond=---- sugar=---3 groove=---- WC-->Major nts=4 GgGG A.G12,A.GTP100,A.G42,A.G46
2 glyco-bond=-s-- sugar=-3-3 groove=wn-- WC-->Major nts=4 GGGG A.G13,A.G40,A.G43,A.G47
step#1 pm(>>,forward) area=7.84 rise=3.35 twist=32.6
strand#1 RNA glyco-bond=-- sugar=-- nts=2 GG A.G12,A.G13
strand#2 RNA glyco-bond=-s sugar=-3 nts=2 gG A.GTP100,A.G40
strand#3 RNA glyco-bond=-- sugar=-- nts=2 GG A.G42,A.G43
strand#4 RNA glyco-bond=-- sugar=33 nts=2 GG A.G46,A.G47
****************************************************************************
List of 2 non-stem G4 loops (INCLUDING the two terminal nts)
1 type=lateral helix=#1 nts=28 GUAGGUCGGUCGCUGCUUCGGCAGUGAG A.G13,A.U14,A.A15,A.G16,A.G17,A.U18,A.C19,A.G20,A.G21,A.U22,A.C23,A.G24,A.C25,A.U26,A.G27,A.C28,A.U29,A.U30,A.C31,A.G32,A.G33,A.C34,A.A35,A.G36,A.U37,A.G38,A.A39,A.G40
2 type=V-shaped helix=#1 nts=4 GGGG A.G40,A.G41,A.G42,A.G43
Pseudoknots
DSSR identifies one pseudoknot in the structure (PDB entry: 9hrf), enabled by the long-range U10-A45 WC pair (see the upper-right panel of the figure above). In literature, pseudoknots are defined by crossing WC pairs. However, in this structure, it is important to note the two synergistic G12+G46 and G13+G47 pairs within two layers of G-tetrads. The two loop regions are thus held tightly together through both pseudoknot and G-quadruplex formation. This observation suggests that the definition of pseudoknots may need to be expanded to include non-canonical pairs.
References
- Stafflinger H, Neißner K, Bartsch S, Pichler AK, Bartosik K, Dhamotharan K, et al. Crystal structure of the class V GTP-binding RNA aptamer bound to its ligand: GTP recognition by a topologically complex intermolecular G-quadruplex. Nucleic Acids Research. 2025;53:gkaf1315. https://doi.org/10.1093/nar/gkaf1315.
- Correll CC. The common and the distinctive features of the bulged-G motif based on a 1.04 A resolution RNA structure. Nucleic Acids Research. 2003;31:6806–18. https://doi.org/10.1093/nar/gkg908.

Since securing funding for the X3DNA-DSSR project through an NIH R24 grant, I have dedicated myself to continuously advancing and refining the software tool. DSSR is a robust and mature tool with a professional user manual. Getting it up and running is straightforward, and assistance for installation is rarely required. Common usages are also already addressed, allowing me to focus on developing new features and addressing edge cases proactively.
- I regularly test DSSR using the latest weekly updates from the Protein Data Bank (PDB), identifying and resolving issues before users report them.
- I actively monitor the 3DNA Forum, providing timely responses to user queries, addressing reported issues, and introducing new features when necessary.
- Writing papers and blog posts can be effective methods to highlight areas where clarification and improvement are needed.
- Collaborating with other researchers often leads to enhancements in DSSR.
- I monitor how DSSR is cited, respond quickly to any reported issues, and contact authors when necessary.
As an example, I noticed a recent article titled 'Structural Analysis of Uridine Modifications in Solved RNA Structures' (https://doi.org/10.1093/nargab/lqaf197) by Arteaga and Znosko, where DSSR was cited as below:
Secondary structure elements (SSEs) containing uridine modifications were identified and annotated using Dissecting the Spatial Structure of RNA (DSSR). Corresponding SSEs containing canonical uridine were identified via RNA Characterization of Secondary Structure Motifs (CoSSMos) and also annotated using DSSR.
Identification and characterization of SSEs RNA SSEs were identified and characterized using the software Disecting the Spatial Structure of RNA (DSSR) [76]. DSSR, an RNA-specific successor to 3DNA [77], was employed to analyze RNA structures containing U modifications. The analysis was performed using default parameters, and all output data were saved in a ∗.json file format. For each ∗.json file, relevant information regarding the U modification residues was extracted. This information included the type of SSE, its associated nucleotide sequence, hydrogen bond acceptor/donor groups, base stacking (π stacking) interactions, sugar pucker, and glycosidic angle. The distance cutoff for identifying hydrogen bonding and base stacking interactions was set to 4.0 Å, as per DSSR’s default settings.
The following citation draw my attention:
An additional 21 structures were excluded from the analysis due to missing atoms in the RCSB PDB entries, DSSR processing issues, incomplete SSEs, or the inability to clip the SSEs (Supplementary Table S2).
I am curious to understand the DSSR processing issues referred to in their study. Upon reviewing 'Supplemental Table S2. Structures excluded from the analysis,' I noted that the following 15 PDB entries were listed as 'Unable to be annotated by DSSR': 4U3M, 4U3U, 4U4Q, 4U4R, 4U4U, 4U52, 4V88, 4V9O, 4V9P, 5FL8, 5TBW, 6I7V, 6SV4, 6Z1P, and 7QVP.
These are all large RNA structures, with 13 of them containing more than 10,000 nucleotides each. I am unsure which version of DSSR was used in their study; however, when using the current version (v2.7.2-2026jan12), I can process these PDB entries without encountering any issues. In cases such as these, or any issues related to 3DNA/DSSR, users are encouraged to reach out. I always aim to address inquiries promptly.
References
- Arteaga SJ, Znosko BM. Structural analysis of uridine modifications in solved RNA structures. NAR Genomics and Bioinformatics. 2026;8:lqaf197. https://doi.org/10.1093/nargab/lqaf197.
The latest release, DSSR v2.7.2-2026jan12, introduces the --pair-wise (or --pairwise) option, which combines the functionalities of the previous --pair-only and --non-pair options. Base-pair identification is a cornerstone of nucleic acid structural analysis, while non-pairing interactions like H-bonds and stacking are also vital structural features. However, the DSSR --non-pair feature is underutilized within the user community. By consolidating these into a single --pair-wise option, we streamline the process of identifying common interactions between nucleotides.
DSSR offers a wide range of nucleic acid structural features, but for users focusing on fundamental DNA/RNA analysis and annotation, the --pair-only option provides simplified functionality. This option instructs DSSR to generate only base-pairing information, which is essential for structural studies. When enabled, --pair-only significantly enhances performance, allowing DSSR to run approximately 10 times faster than in its default configuration. Running DSSR on the yeast phenylalanine tRNA (PDB 1ehz) with the --pair-only option leads to the following output instantaneously:
# x3dna-dssr -i=1ehz.pdb --pair-only
List of 34 base pairs
nt1 nt2 bp name Saenger LW DSSR
1 A.G1 A.C72 G-C WC 19-XIX cWW cW-W
2 A.C2 A.G71 C-G WC 19-XIX cWW cW-W
3 A.G3 A.C70 G-C WC 19-XIX cWW cW-W
4 A.G4 A.U69 G-U Wobble 28-XXVIII cWW cW-W
5 A.A5 A.U68 A-U WC 20-XX cWW cW-W
6 A.U6 A.A67 U-A WC 20-XX cWW cW-W
7 A.U7 A.A66 U-A WC 20-XX cWW cW-W
8 A.U8 A.A14 U-A rHoogsteen 24-XXIV tWH tW-M
9 A.U8 A.A21 U+A -- -- tSW tm+W
10 A.A9 A.A23 A+A -- 02-II tHH tM+M
11 A.2MG10 A.C25 g-C WC 19-XIX cWW cW-W
12 A.2MG10 A.G45 g+G -- -- cHS cM+m
13 A.C11 A.G24 C-G WC 19-XIX cWW cW-W
14 A.U12 A.A23 U-A WC 20-XX cWW cW-W
15 A.C13 A.G22 C-G WC 19-XIX cWW cW-W
16 A.G15 A.C48 G+C rWC 22-XXII tWW tW+W
17 A.H2U16 A.U59 u+U -- -- tSW tm+W
18 A.G18 A.PSU55 G+P -- -- tWS tW+m
19 A.G19 A.C56 G-C WC 19-XIX cWW cW-W
20 A.G22 A.7MG46 G-g -- 07-VII tHW tM-W
21 A.M2G26 A.A44 g-A Imino 08-VIII cWW cW-W
22 A.C27 A.G43 C-G WC 19-XIX cWW cW-W
23 A.C28 A.G42 C-G WC 19-XIX cWW cW-W
24 A.A29 A.U41 A-U WC 20-XX cWW cW-W
25 A.G30 A.5MC40 G-c WC 19-XIX cWW cW-W
26 A.A31 A.PSU39 A-P -- -- cWW cW-W
27 A.OMC32 A.A38 c-A -- -- c.W c.-W
28 A.U33 A.A36 U-A -- -- tSH tm-M
29 A.5MC49 A.G65 c-G WC 19-XIX cWW cW-W
30 A.U50 A.A64 U-A WC 20-XX cWW cW-W
31 A.G51 A.C63 G-C WC 19-XIX cWW cW-W
32 A.U52 A.A62 U-A WC 20-XX cWW cW-W
33 A.G53 A.C61 G-C WC 19-XIX cWW cW-W
34 A.5MU54 A.1MA58 t-a rHoogsteen 24-XXIV tWH tW-M
With the --non-pair option, DSSR identifies H-bonding and base-stacking interactions between two nucleotides that do not form a pair. This option is an additional feature integrated into DSSR, expanding its capabilities by including these non-pairing interactions in the main output alongside pairing information, among other functionalities. Running DSSR on the yeast phenylalanine tRNA (PDB 1ehz) with the --non-pair option identifies 91 non-pairing interactions, with the first 16 listed below.
# x3dna-dssr -i=1ehz.pdb
List of 91 non-pairing interactions
1 A.G1 A.C2 stacking: 5.4(2.6)--pm(>>,forward) interBase-angle=5 connected min-baseDist=3.26
2 A.G1 A.A73 stacking: 2.4(1.2)--mm(<>,outward) interBase-angle=3 min-baseDist=3.17
3 A.C2 A.G3 stacking: 0.5(0.0)--pm(>>,forward) interBase-angle=9 connected min-baseDist=3.41
4 A.G3 A.G4 stacking: 3.2(1.8)--pm(>>,forward) interBase-angle=10 H-bonds[1]: "O2'(hydroxyl)-O4'[3.11]" connected min-baseDist=3.24
5 A.G3 A.G71 stacking: 2.6(0.3)--mm(<>,outward) interBase-angle=5 min-baseDist=3.02
6 A.G4 A.A5 stacking: 5.6(3.5)--pm(>>,forward) interBase-angle=6 connected min-baseDist=3.13
7 A.A5 A.U6 stacking: 5.9(4.3)--pm(>>,forward) interBase-angle=9 connected min-baseDist=3.12
8 A.U6 A.U7 stacking: 0.6(0.0)--pm(>>,forward) interBase-angle=20 connected min-baseDist=3.11
9 A.U7 A.5MC49 stacking: 1.2(0.0)--pm(>>,forward) interBase-angle=7 H-bonds[1]: "O2'(hydroxyl)-OP2[2.68]" min-baseDist=3.64
10 A.U8 A.C13 stacking: 2.0(0.0)--pp(><,inward) interBase-angle=13 min-baseDist=3.34
11 A.U8 A.G15 stacking: 0.5(0.0)--mm(<>,outward) interBase-angle=14 min-baseDist=3.27
12 A.A9 A.C11 interBase-angle=27 H-bonds[1]: "O2'(hydroxyl)-N4(amino)[2.90]" min-baseDist=3.72
13 A.A9 A.C13 interBase-angle=9 H-bonds[1]: "OP2-N4(amino)[3.01]" min-baseDist=4.65
14 A.A9 A.G22 stacking: 0.1(0.0)--mp(<<,backward) interBase-angle=13 min-baseDist=3.37
15 A.A9 A.G45 stacking: 1.6(0.5)--pp(><,inward) interBase-angle=10 min-baseDist=3.30
16 A.A9 A.7MG46 stacking: 1.6(0.7)--mm(<>,outward) interBase-angle=4 H-bonds[1]: "O5'-N2(amino)[3.34]" min-baseDist=3.38
......
DSSR calculates base-stacking by determining the overlap area (in Ų) between two interacting bases. The calculation involves projecting the atoms of the two bases onto their mean plane to define the overlapping region, from which the area is derived. In the output, values in parentheses represent the overlap area based solely on ring atoms, while those outside parentheses include contributions from exocyclic atoms as well (see Lu and Olson, 2003; Lu et al., 2015).
Base-stacking interactions are classified into one of four categories:
- pm (>>, forward): Interaction occurs on the plus-minus faces of the two bases in a forward direction.
- mp (<<, backward): Interaction occurs on the minus-plus faces of the two bases in a backward direction.
- mm (<>, outward): Interaction occurs between two minus faces oriented outward.
- pp (><, inward): Interaction occurs between two plus faces oriented inward.
In this classification:
p represents the plus face of the base ring, andm represents the minus face.
These categories are defined by the direction of the z-axis in the standard base reference frame (Olson et al., 2001). The symbols (>>, <<, <>, and ><) follow Parisien et al. (2009), with the exception that:
- pm (>>) is referred to as "forward" instead of "upward," and
- mp (<<) is referred to as "backward" instead of "downward."
The new --pair-wise option functions similarly to the --pair-only option by generating a separate output file. However, unlike --pair-only, it also includes non-pairing interactions in this file. DSSR runs faster than the full analysis because it characterizes only base-pairing and non-pairing interactions. Additionally, the --more and --json options are supported, enabling users to derive more detailed features (e.g., local base-pair parameters and H-bonds in base pairs) and easily parse them using JSON output.
Running DSSR on the yeast phenylalanine tRNA (PDB 1ehz) with the --pair-wise option identifies 34 base pairs and 91 non-pairing interactions, as expected. When combined with the --more and --json options, the output is summarized below.
# x3dna-dssr -i=1ehz.pdb --pair-wise --more --json | fx
{
"num_pairs": 34,
"pairs": […],
"num_nonPairs": 91,
"nonPairs": […],
"program": "DSSR v2.7.2-2026jan12 by xiangjun@x3dna.org"
}
Please refer to the DSSR User Manual for comprehensive explanations of all available features.
References
- Lu X-J, Olson WK. 3DNA: a software package for the analysis, rebuilding and visualization of three-dimensional nucleic acid structures. Nucleic Acids Res. 2003;31:5108–21. https://doi.org/10.1093/nar/gkg680.
- Lu X-J, Bussemaker HJ, Olson WK. DSSR: an integrated software tool for dissecting the spatial structure of RNA. Nucleic Acids Res. 2015;:gkv716. https://doi.org/10.1093/nar/gkv716.
- Olson WK, Bansal M, Burley SK, Dickerson RE, Gerstein M, Harvey SC, et al. A standard reference frame for the description of nucleic acid base-pair geometry. Journal of Molecular Biology. 2001;313:229–37. https://doi.org/10.1006/jmbi.2001.4987.
- Parisien M, Cruz JA, Westhof É, Major F. New metrics for comparing and assessing discrepancies between RNA 3D structures and models. RNA. 2009;15:1875–85. https://doi.org/10.1261/rna.1700409.
Recently, I read the preprint of Gordan et al. (2025), titled "High-throughput characterization of transcription factors that modulate UVdamage formation and repair at single-nucleotide resolution". In the METHODS section on "Structural analysis of AlphaFold 3 predicted TF-DNA complexes", the authors introduced two geometric parameters to characterize dipyrimidines, as detailed below:
Base-step d22 distance, d64 distance, of dipyrimidines were computed for each base-step per DNA strand using custom PyMOL python scripts74. d22 was defined as the distance in Ångstroms (Å) between the C5-C6 bond midpoints between adjacent pyrimidines. d64 was defined as the Å distance between the 5' pyrimidine's C5 and X4 (either O or N) attached to the 3' pyrimidine's C4.
These d22 and d64 parameters are well-defined and straightforward to calculate (see the figure below for illustrative examples). They can be integrated seamlessly with DSSR's infrastructure, requiring minimal additional coding effort. As a result, I have decided to implement them into DSSR.
For example, in the case of the MyoD bHLH domain-DNA complex (PDB ID: 1mdy), running the following DSSR (v2.7.1) command:
x3dna-dssr -i=1mdy.pdb --json -o=1mdy.json
generates a JSON file (1mdy.json), which contains the following information under the nts section for E.DT1 (connected with E.DC2): "d22": 4.014 and "d64": 3.655."
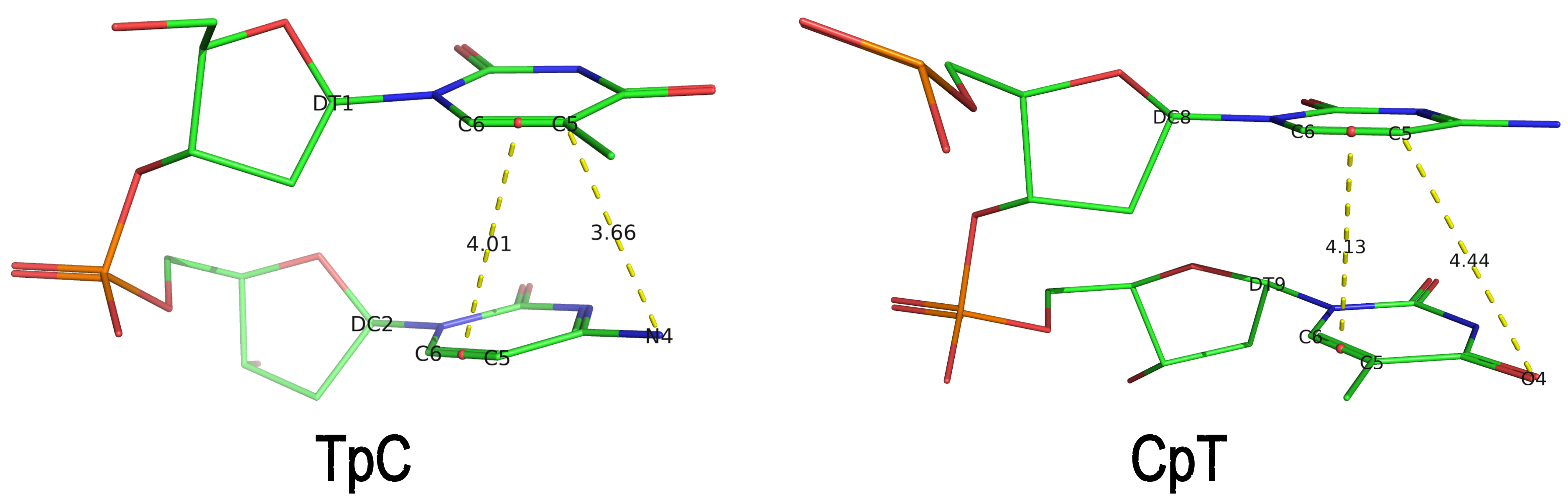 The default human-readable output file,
The default human-readable output file, dssr-torsions.txt, now includes two additional columns for d22 and d64 under the section titled 'Main chain conformational parameters,' as shown below.
nt d22 d64
1 T E.DT1 4.01 3.66
2 C E.DC2 --- ---
3 A E.DA3 --- ---
4 A E.DA4 --- ---
5 C E.DC5 --- ---
6 A E.DA6 --- ---
7 G E.DG7 --- ---
8 C E.DC8 4.13 4.44
9 T E.DT9 --- ---
Note that pseudouridine (Ψ) is excluded from the calculation of d22 and d64 parameters of a dipyrimidine base step.
The implementation of d22 and d64 parameters in DSSR is a clear example of my proactive approach to enhancing the software's functionality. Users are always encouraged to reach out with requests for new features or improvements, as well as to report any bugs or ask questions.
References
- Gordan R, Wasserman H, Chi B, Bohm K, Duan M, Sahay H, et al. High-throughput characterization of transcription factors that modulate UVdamage formation and repair at single-nucleotide resolution. 2025. https://doi.org/10.21203/rs.3.rs-8197218/v1.
 March 2026
March 2026
 February 2026
February 2026
Cover image provided by X3DNA-DSSR, an NIGMS National Resource for Structural Bioinformatics of Nucleic Acids (R24GM153869; skmatics.x3dna.org). Image generated using DSSR and PyMOL (Lu XJ. 2020. Nucleic Acids Res 48: e74).
As the developer of DSSR, I am thrilled to see its application in cutting-edge research across multiple disciplines. Below is a list of four recent publications that highlight how DSSR has been utilized, underscoring its versatility and significance in structural bioinformatics.
In the Geng et al. (2025) Nucleic Acids Research (NAR) paper, titled 'Revealing hidden protonated conformational states in RNA dynamic ensembles', DSSR is simply cited as follows:
All bp geometries, hydrogen-bond, backbone, stacking, and sugar dihedral angles were calculated using X3DNA-DSSR [77].
In the preprint by Gordan et al. (2025), titled 'High-throughput characterization of transcription factors that modulate UV damage formation and repair at single-nucleotide resolution', DSSR is cited as follows:
Step base stacking, base pair shift, base pair slide, interbase angle, pseudorotation angle, and sugar puckering classifications of nucleobases were computed using X3DNA-DSSR (v2.5.0)75. Base stacking was defined as the overlapping polygon area in Å2 when projecting the dipyrimidine base ring atoms (excluding exocyclic atoms) into the mean base pair plane76. The sugar ring pseudorotation phase angle of each pyrimidine was also calculated using X3DNA-DSSR as described by Altona, C. & Sundaralingam, M.77 Interbase angle was defined as sqrt(propeller2+buckle2) per the X3DNA-DSSR documentation.
Figure 6: TF Binding Induces Structural Distortion Favorable to UV Dimerization is highly informative, particularly panel (a), which illustrates the ensemble of structural parameters that predispose dipyrimidines to cyclobutane pyrimidine dimers (CPD) or 6-4 pyrimidine-pyrimidones (6-4 PP) formation. DSSR is designed as an integrated software tool, offering a comprehensive suite of structural parameters not found in any other single tool I am aware of. Despite this, the innovative use of DSSR by Gordan et al. exceeds my expectations and demonstrates its versatility.
In the preprint by Kubaney et al. (2025) from the Baker group, titled 'RNA sequence design and protein-DNA specificity prediction with NA-MPNN', DSSR is cited as follows:
On the pseudoknot subset, we evaluate additional structure‐ and reactivity‐based metrics. DSSR v2.3.241 is used to extract the ground‐truth secondary structure from the native crystal structures. For each designed sequence, RibonanzaNet predicts 2A3 reactivity profiles, from which we compute predicted OpenKnot scores (see https://github.com/eternagame/OpenKnotScore)31 using the predicted reactivity together with the DSSR ground truth.
In a recent NSMB paper from the Baker group, titled 'Computational design of sequence-specific DNA-binding proteins', 3DNA is cited as follows:
RIF docking of scaffolds onto DNA targets (DBP design step 1) Structures of B-DNA for each target (Supplementary Table 2) were generated by (1) using the DNA portion of PDB 1BC8 (ref. 60), PDB 1YO5 (ref. 61), PDB 1L3L (ref. 51) or PDB 2O4A (ref. 62) or (2) using the software X3DNA63, followed by a constrained Rosetta relax of the DNA structure.
Please note that 3DNA has been replaced by DSSR. The functionality for constructing B-DNA models, previously provided by 3DNA, is now directly available in DSSR via its fiber and rebuild modules.
In the preprint by Si et al. (2025), titled 'End-to-End Single-Stranded DNA Sequence Design with All-Atom Structure Reconstruction', DSSR is cited as follows:
Since ViennaRNA and NUPACK require secondary structures as input, we used DSSR35 to extract secondary structures from the corresponding ssDNA three-dimensional structures.
The above use cases are merely a sample of how DSSR is utilized in the scientific literature. It is reasonable to state that DSSR has emerged as a de facto standard tool within the field of nucleic acid structural bioinformatics. Overall, DSSR is a mature, robust, and efficient software product that is actively developed and maintained. I am committed to making DSSR synonymous with quality and value. Its unmatched functionality, usability, and support save users significant time and effort compared to alternative solutions.
DSSR is available free of charge for academic users. Additionally, it has been integrated into other high-profile bioinformatics resources, including NAKB, PDB-redo, and N•ESPript.
References
- Geng A, Roy R, Ganser L, Li L, Al-Hashimi HM. Revealing hidden protonated conformational states in RNA dynamic ensembles. Nucleic Acids Research. 2025;53:gkaf1366. https://doi.org/10.1093/nar/gkaf1366.
- Gordan R, Wasserman H, Chi B, Bohm K, Duan M, Sahay H, et al. High-throughput characterization of transcription factors that modulate UV damage formation and repair at single-nucleotide resolution. 2025. https://doi.org/10.21203/rs.3.rs-8197218/v1.
- Kubaney A, Favor A, McHugh L, Mitra R, Pecoraro R, Dauparas J, et al. RNA sequence design and protein–DNA specificity prediction with NA-MPNN. 2025. https://doi.org/10.1101/2025.10.03.679414.
- Glasscock CJ, Pecoraro RJ, McHugh R, Doyle LA, Chen W, Boivin O, et al. Computational design of sequence-specific DNA-binding proteins. Nat Struct Mol Biol. 2025;32:2252–61. https://doi.org/10.1038/s41594-025-01669-4.
- Si Y, Xu Y, Chen L. End-to-end single-stranded DNA sequence design with all-atom structure reconstruction. 2025. https://doi.org/10.64898/2025.12.05.692525.
By following DSSR citations, I recently came across the paper by Saon et al. (2025), titled 'Identification and characterization of shifted G•U wobble pairs resulting from alternative protonation of RNA.' This paper provides a detailed analysis of shifted G-U wobble pairs in RNA, characterized by the opposite positioning of G vs. U in the standard G-U wobble pair (see figure below). Conventionally, a G-U wobble has the U located in the major groove, whereas a shifted G-U wobble has the G located in the major groove.
Specifically, the shifted G-U wobble pair involves an H-bond between the N2(G) and N3(U) atoms, which would be donor-donor if U were in its neutral form. There are three ways to rationalize the formation of this H-bond: (1) anionic U as originally proposed by Westhof et al. (2023), (2) U-enolate, and (3) G-imino tautomeric forms as illustrated by Saon et al. (2025). Since the position of the H-atoms cannot be determined from X-ray diffraction and cryo-EM structures, it is not possible (in my understanding) to determine which of these three mechanisms is correct—perhaps it involves a combination of them. What is clear is that the shifted G-U wobble pair is supported by strong experimental evidence from diverse sources. The authors identified 373 high-confidence shifted G-U wobble pairs across four separate structural clusters, spanning all three domains of life.
 Structure of standard and shifted G-U wobble pairs. The examples are taken from PDB entry 8B0X (Fromm et al., 2023) and generated using DSSR and PyMOL. Atom names in the Watson-Crick edges are shown in red and blue for oxygen and nitrogen, respectively. Hydrogen bonds are depicted as dashed lines in magenta. The unusual N2(G)...N3(U) hydrogen bond is marked with a star; it would be donor-donor if U were in its neutral form. The shaded illustration at the bottom is taken from Saon et al., showing shifted G-U wobble pairs in anionic, U-enolate, and G-imino tautomeric forms.
Structure of standard and shifted G-U wobble pairs. The examples are taken from PDB entry 8B0X (Fromm et al., 2023) and generated using DSSR and PyMOL. Atom names in the Watson-Crick edges are shown in red and blue for oxygen and nitrogen, respectively. Hydrogen bonds are depicted as dashed lines in magenta. The unusual N2(G)...N3(U) hydrogen bond is marked with a star; it would be donor-donor if U were in its neutral form. The shaded illustration at the bottom is taken from Saon et al., showing shifted G-U wobble pairs in anionic, U-enolate, and G-imino tautomeric forms.
I'm glad to see that DSSR has been used in the analysis, as shown in the following excerpts from the paper.
The selected structures were then characterized by Dissecting the Spatial Structure of RNA (DSSR) software [34]. This step output base pair, hydrogen bond, stacking, glycosidic angle, and sugar pucker information for each structure file.
From the DSSR base pair information, all G•U base pairs were identified and filtered as wobble or non-wobble base pairs. All base pairs called by DSSR as G•U wobbles were considered for the next steps of the analysis as standard wobbles. Any base pairs containing hydrogen bonds between G(N1) and U(O4), as well as G(N2) and U(N3) (see Fig. 1) were binned to shifted wobble base pairs.
From the base pair information extracted from the DSSR characterization output, the non-redundant G•U wobbles were binned based on their location in one of the five secondary structure motifs: (1) inside stem, with one WCF base pair above and one below, (2) terminal, with at least one WCF base pair above, (3) terminal, with at least one WCF base pair below, (4) unstructured, where no WCF base pair is right above or below and the wobble does not occur at the closing base pair of a hairpin loop with a maximum of 10 nucleotides, and (5) inside a loop.
Next, for each of the five members, we retrieved the 3D structure of the 20 residues from the respective pdb files and obtained the underlying secondary structures for each of the five files in dot bracket notation using DSSR [34].
DSSR implements a geometric approach to identify hydrogen bonds, including unconventional donor/acceptor combinations (e.g., the N3-to-N3 hydrogen bond in the hemiprotonated cytosine–cytosine base pair in the i-motif). It is capable of identifying all pairs that actually exist in a given structure, whether they are canonical (Watson-Crick or G-U wobble) or non-canonical. The latter pairs may include normal or modified nucleotides, regardless of their tautomeric or protonation state.
Thus, DSSR detects standard G-U wobble pairs and names them as such ('Wobble'). Moreover, it also detects shifted G-U wobble pairs and previously named them as '~Wobble,' meaning similar to a standard wobble pair. Note that the '~Wobble' designation is based on the geometric approach of DSSR, which involves the cW-W relative orientation of the two bases and a large shear value. It is not limited to wobble pairs between G and U.
After reading the Saon et al. paper, I have revised DSSR to specifically characterize shifted G-U wobble pairs and named them as 'sWobble.' The term 'shifted-Wobble' would be too long for the DSSR text output, and using 's' also reflects the shear parameter, which is key in characterizing wobble pairs. As a concrete example, the following DSSR command
x3dna-dssr -i=8B0X.cif --pair-only --more -o=8B0X-pairs.out
would generate the below output in the file 8B0X-pairs.out. Note the name sWobble, the hydrogen bond N3(imino)*N2(amino)[3.26] with a * to indicate an unusual donor/acceptor combination, and the -2.33 shear value.
607 A.U1086 A.G1099 U-G sWobble -- cWW cW-W
[-171.2(anti) ~C3'-endo lambda=33.9] [-170.0(anti) ~C3'-endo lambda=59.2]
d(C1'-C1')=11.57 d(N1-N9)=9.60 d(C6-C8)=10.07 tor(C1'-N1-N9-C1')=8.8
H-bonds[2]: "N3(imino)*N2(amino)[3.26],O4(carbonyl)-N1(imino)[2.64]"
interBase-angle=26 Simple-bpParams: Shear=-2.23 Stretch=0.69 Buckle=22.1 Propeller=-13.8
bp-pars: [-2.33 0.13 -0.80 24.83 -7.98 -20.38]
The new DSSR version can automatically detect all 373 high-confidence shifted G-U wobble pairs listed in Table S3 of the Saon et al. paper. It will be released soon. This is yet another example of how DSSR is being actively improved to better serve the research community.
References
- Saon,M.S. et al. (2025) Identification and characterization of shifted G•U wobble pairs resulting from alternative protonation of RNA. Nucleic Acids Research, 53, gkaf575.
- Westhof,E. et al. (2023) Anionic G•U pairs in bacterial ribosomal rRNAs. RNA, 29, 1069–1076.
- Fromm,S.A. et al. (2023) The translating bacterial ribosome at 1.55 Å resolution generated by cryo-EM imaging services. Nat Commun, 14, 1095.
As of v2.5.4-2025jun06, DSSR automatically checks for steric clashes or exact duplicates of residues in an input coordinate file. It reports such issues instead of crashing, and will terminate only if an excessive number of overlaps are detected. An simplified example is shown below, which contains two nucleotides (G#1) on chains 0 and 1, respectively
ATOM 1 OP3 G 0 1 -4.270 51.892 37.186 1.00 27.93 O
ATOM 2 P G 0 1 -3.834 50.887 37.436 1.00 28.61 P
ATOM 3 OP1 G 0 1 -4.601 49.700 37.549 1.00 27.02 O
ATOM 4 OP2 G 0 1 -4.061 52.011 36.684 1.00 25.80 O
ATOM 5 O5' G 0 1 -2.906 51.105 38.691 1.00 28.01 O
ATOM 6 C5' G 0 1 -1.941 52.126 38.781 1.00 26.76 C
ATOM 7 C4' G 0 1 -1.037 51.914 39.967 1.00 26.12 C
ATOM 8 O4' G 0 1 -1.822 51.894 41.184 1.00 24.21 O
ATOM 9 C3' G 0 1 -0.285 50.591 39.988 1.00 25.12 C
ATOM 10 O3' G 0 1 0.884 50.614 39.172 1.00 26.09 O
ATOM 11 C2' G 0 1 0.008 50.411 41.462 1.00 26.05 C
ATOM 12 O2' G 0 1 1.102 51.209 41.880 1.00 27.46 O
ATOM 13 C1' G 0 1 -1.271 50.952 42.083 1.00 28.40 C
ATOM 14 N9 G 0 1 -2.272 49.904 42.329 1.00 27.27 N
ATOM 15 C8 G 0 1 -3.470 49.733 41.686 1.00 26.55 C
ATOM 16 N7 G 0 1 -4.137 48.712 42.125 1.00 25.36 N
ATOM 17 C5 G 0 1 -3.332 48.176 43.118 1.00 25.64 C
ATOM 18 C6 G 0 1 -3.529 47.056 43.955 1.00 24.98 C
ATOM 19 O6 G 0 1 -4.492 46.284 43.991 1.00 24.56 O
ATOM 20 N1 G 0 1 -2.460 46.862 44.821 1.00 24.78 N
ATOM 21 C2 G 0 1 -1.346 47.639 44.878 1.00 24.96 C
ATOM 22 N2 G 0 1 -0.417 47.298 45.782 1.00 23.72 N
ATOM 23 N3 G 0 1 -1.145 48.689 44.109 1.00 25.74 N
ATOM 24 C4 G 0 1 -2.171 48.901 43.257 1.00 26.32 C
ATOM 1 OP3 G 1 1 -6.437 51.060 40.254 1.00 27.81 O
ATOM 2 P G 1 1 -5.327 50.209 39.884 1.00 28.55 P
ATOM 3 OP1 G 1 1 -5.668 48.792 39.652 1.00 26.90 O
ATOM 4 OP2 G 1 1 -4.838 51.036 38.808 1.00 25.57 O
ATOM 5 O5' G 1 1 -4.301 50.297 41.090 1.00 27.94 O
ATOM 6 C5' G 1 1 -3.427 51.393 41.257 1.00 26.67 C
ATOM 7 C4' G 1 1 -2.528 51.168 42.443 1.00 26.12 C
ATOM 8 O4' G 1 1 -3.335 50.964 43.624 1.00 24.16 O
ATOM 9 C3' G 1 1 -1.648 49.928 42.372 1.00 25.13 C
ATOM 10 O3' G 1 1 -0.467 50.136 41.599 1.00 26.15 O
ATOM 11 C2' G 1 1 -1.372 49.649 43.835 1.00 25.96 C
ATOM 12 O2' G 1 1 -0.375 50.515 44.354 1.00 27.37 O
ATOM 13 C1' G 1 1 -2.714 50.006 44.458 1.00 28.21 C
ATOM 14 N9 G 1 1 -3.608 48.845 44.581 1.00 27.06 N
ATOM 15 C8 G 1 1 -4.771 48.614 43.895 1.00 26.37 C
ATOM 16 N7 G 1 1 -5.340 47.496 44.226 1.00 25.18 N
ATOM 17 C5 G 1 1 -4.502 46.957 45.190 1.00 25.44 C
ATOM 18 C6 G 1 1 -4.599 45.755 45.923 1.00 24.77 C
ATOM 19 O6 G 1 1 -5.480 44.892 45.864 1.00 24.39 O
ATOM 20 N1 G 1 1 -3.532 45.594 46.796 1.00 24.63 N
ATOM 21 C2 G 1 1 -2.504 46.469 46.949 1.00 24.81 C
ATOM 22 N2 G 1 1 -1.560 46.145 47.845 1.00 23.58 N
ATOM 23 N3 G 1 1 -2.396 47.594 46.280 1.00 25.56 N
ATOM 24 C4 G 1 1 -3.422 47.779 45.423 1.00 26.12 C
Running DSSR on the above coordinates will show the following output:
[i] 0.G1 and 1.G1 in clashes: min_dist=0.57
where min_dist refers to the minimum distance between heavy atoms of the two nucleotides.
The clash-detection feature in DSSR was added in response to the bioRxiv preprint by Kretsch et al. (2025), titled "Assessment of nucleic acid structure prediction in CASP16" (https://doi.org/10.1101/2025.05.06.652459), which noted that in some predicted RNA models submitted to CASP16, multiple models were not properly delineated with MODEL/ENDMDL in PDB format or _atom_site.pdbx_PDB_model_num in mmCIF format. I communicated with the authors, who kindly provided the PDB files to help debug the issue. For more details, see the blog post Improving DSSR through extreme cases from early June 2025 at https://x3dna.org/highlights/improving-dssr-through-extreme-cases.
The bioRxiv paper by Kretsch et al. was recently published in Proteins: Structure, Function, and Bioinformatics. The relevant citation to DSSR is in Section 2.8 | Secondary Structure Analysis, as follows:
Secondary structures were extracted from CASP16 models with DSSR (v1.9.9-2020feb06) [47]. Some models, in particular due to large clashes, could not be processed by DSSR (Table S1). The base-pair list was extracted from the table in the output file directly because the dot-bracket structure produced by DSSR, in particular for multimers, contained errors. The canonical base pairs were defined as those labeled as Watson-Crick-Franklin (WC) and wobble base pairs (hereafter referred to as ‘base pairs’ or ‘pairs’). All other base pairs are defined as non-canonical base pairs and analyzed separately. Crossed base pairs (pseudoknots) were defined as non-nested canonical base pairs, that is, any canonical base pair (i,j) for which another canonical base pair (k,l) existed with i < k < j < l or k < i < l < j. Singlet base pairs were defined as any canonical base pair that was not part of a stem, that is, (i,j) such that there was no neighboring canonical base pair between i + 1 and j − 1 or between i − 1 and j + 1. Intermolecular base pairs were identified as any canonical base pair between nucleotides in different chains.
It is worth noting that DSSR is actively supported, and I always strive to respond to users’ questions via email or (preferably) on the 3DNA Forum quickly and concretely. If you have any questions about DSSR or need clarifications, please feel free to contact me. Additionally, I monitor 3DNA/DSSR citations in the literature and proactively address issues that come to my attention when necessary.
I recently came across the paper by Zurkowski et al. (2025), titled "Detecting polynucleotide motifs: Pentads, hexads, and beyond.". The authors introduce LinkTetrado, a software tool that is described as "the first fully automated method for detecting polyadic motifs in the three-dimensional structures of nucleic acids." I am somewhat surprised by this claim, as I believe it overlooks the 2015 DSSR paper, which includes a dedicated section on "Higher-order coplanar base associations (multiplets)" as shown below:
DSSR defines multiplets as three or more bases associated in a coplanar geometry via a network of hydrogen-bonding interactions. Multiplets are identified through inter-connected base pairs, filtered by pair-wise stacking interactions and vertical separations to ensure overall coplanarity (Supplementary Figures S1, S3, S4 and S7). The abundant A-minor motifs (33) (types I and II, Supplementary Figures S3, S4 and S7) are base triplets, the smallest multiplet. The G-tetrad motif, where four guanines are associated via four pairs in a square planar geometry, is another special case of a multiplet.
In fact, DSSR multiplets are all-encompassing, including pentads, hexads, heptads, octads, etc.
The DSSR User Manual has extensive discussions (see Section 3.2.4 "Multiplets (higher-order coplanar base associations)") and several examples of multiplets, including:
- Figure 8: The GUA triplet auto-identified by DSSR in PDB entry 1msy.
- Figure 12: Base pentad (AUAAG) auto-identified by DSSR in PDB entry 1jj2. The five nts (A306,U325,A331,A340,G345) are all within the 23S rRNA.
DSSR can successfully identify the multiplets reported in the Zurkowski et al. paper, although there may be minor differences due to variations in cutoffs and definitions. For instance, using PDB ID 6w9p (shown in Fig. 7F of the Zurkowski et al. paper), DSSR can perform the following:
x3dna-dssr -i=6w9p.pdb -o=6w9p.out
x3dna-dssr -i=dssr-multiplets.pdb --select-model=4 -o=G4T3.pdb
The relevant portions of DSSR output (6w9p.out) are shown below:
List of 4 multiplets
1 nts=4 GGGG A.DG4,A.DG10,A.DG16,A.DG22
2 nts=4 GGGG A.DG5,A.DG11,A.DG17,A.DG23
3 nts=4 GGGG A.DG7,A.DG13,A.DG19,A.DG25
4 nts=7 GTGTGTG A.DG6,A.DT9,A.DG12,A.DT15,A.DG18,A.DT21,A.DG24
...
2 dssr-multiplets.pdb -- an ensemble of multiplets
DSSR can further render the extracted G4T3.pdb into the following image using PyMOL:

DSSR has far more to offer than meets the eye. See the DSSR User Manual and the practical guide to DSSR-PyMOL integration for more details.
References
Lu,X.-J. et al. (2015) DSSR: an integrated software tool for dissecting the spatial structure of RNA. Nucleic Acids Res, gkv716.
Zurkowski,M. et al. (2025) Detecting polynucleotide motifs: Pentads, hexads, and beyond. PLoS Comput Biol, 21, e1013633.
Recently, I noticed that a user had uploaded a file to the website "DSSR-enabled Innovative Schematics of 3D Nucleic Acid Structures with PyMOL", which DSSR reported as 'no nucleotides found.' Upon visualizing it in PyMOL, the structure appeared to be a single-stranded RNA. Further investigation revealed that while the uploaded file was in PDB format, it did not adhere to the standard naming conventions for nucleotides typically used in RCSB PDB entries. For instance, an A nucleotide extracted from the file had its exocyclic amino group named as N553 instead of the conventional N6 (see below).
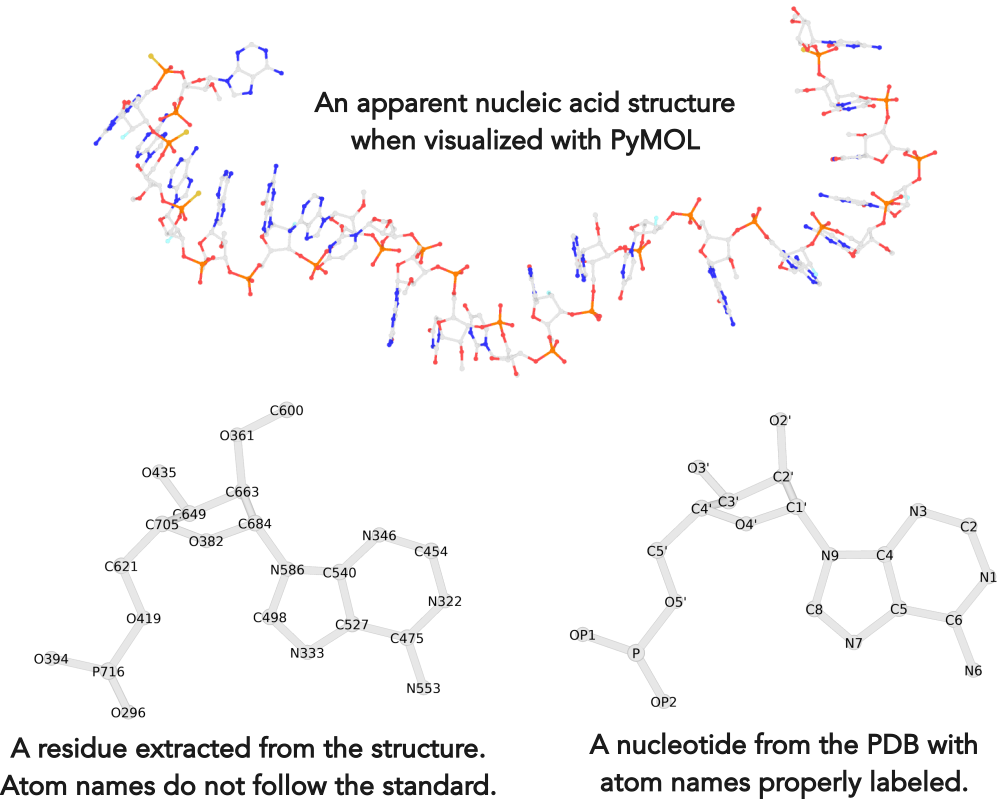
Following 3DNA, DSSR uses the atomic coordinates and standard names of base-ring atoms to identify a nucleotide. All known nucleotides share a common six-membered pyrimidine ring, with atoms named consecutively (N1, C2, N3, C4, C5, C6), and purines include three additional atoms (N7, C8, N9). See below for the standard names in Watson-Crick base pairs.
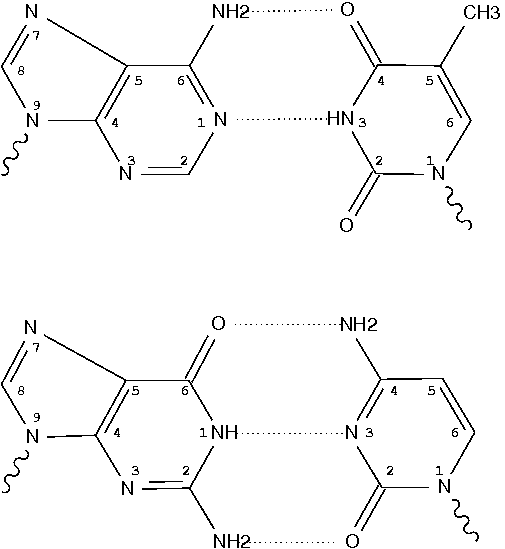
Without proper names for base ring atoms, DSSR is unable to identify nucleotides, resulting in the input structure being reported as 'no nucleotides found.' The same principle applies to amino acids in protein structures, such as specific naming conventions for amino nitrogen (N), carbonyl carbon (C), and alpha carbon (CA).
See also the blog posts "Mapping of modified nucleotides in DSSR" and "Name of base atoms in PDB formats".