Cover image provided by X3DNA-DSSR, an NIGMS National Resource for structural bioinformatics of nucleic acids (R24GM153869; skmatics.x3dna.org). Image generated using DSSR and PyMOL (Lu XJ. 2020. [Nucleic Acids Res 48: e74(https://doi.org/10.1093/nar/gkaa426)).
See the 2020 paper titled "DSSR-enabled innovative schematics of 3D nucleic acid structures with PyMOL" in Nucleic Acids Research and the corresponding Supplemental PDF for details. Many thanks to Drs. Wilma Olson and Cathy Lawson for their help in the preparation of the illustrations.
Details on how to reproduce the cover images are available on the 3DNA Forum.

Structure of a group II intron ribonucleoprotein in the pre-ligation state (PDB id: 8T2R; Xu L, Liu T, Chung K, Pyle AM. 2023. Structural insights into intron catalysis and dynamics during splicing. Nature 624: 682–688). The pre-ligation complex of the Agathobacter rectalis group II intron reverse transcriptase/maturase with intron and 5′-exon RNAs makes it possible to construct a picture of the splicing active site. The intron is depicted by a green ribbon, with bases and Watson-Crick base pairs represented as color-coded blocks: A/A-U in red, C/C-G in yellow, G/G-C in green, U/U-A in cyan; the 5′-exon is shown by white spheres and the protein by a gold ribbon. Cover image provided by X3DNA-DSSR, an NIGMS National Resource for structural bioinformatics of nucleic acids (R24GM153869; skmatics.x3dna.org). Image generated using DSSR and PyMOL (Lu XJ. 2020. Nucleic Acids Res 48: e74).

Complex of terminal uridylyltransferase 7 (TUT7) with pre-miRNA and Lin28A (PDB id: 8OPT; Yi G, Ye M, Carrique L, El-Sagheer A, Brown T, Norbury CJ, Zhang P, Gilbert RJ. 2024. Structural basis for activity switching in polymerases determining the fate of let-7 pre-miRNAs. Nat Struct Mol Biol 31: 1426–1438). The RNA-binding pluripotency factor LIN28A invades and melts the RNA and affects the mechanism of action of the TUT7 enzyme. The RNA backbone is depicted by a red ribbon, with bases and Watson-Crick base pairs represented as color-coded blocks: A/A-U in red, C/C-G in yellow, G/G-C in green, U/U-A in cyan; TUT7 is represented by a gold ribbon and LIN28A by a white ribbon. Cover image provided by X3DNA-DSSR, an NIGMS National Resource for structural bioinformatics of nucleic acids (R24GM153869; skmatics.x3dna.org). Image generated using DSSR and PyMOL (Lu XJ. 2020. Nucleic Acids Res 48: e74).

Cryo-EM structure of the pre-B complex (PDB id: 8QP8; Zhang Z, Kumar V, Dybkov O, Will CL, Zhong J, Ludwig SE, Urlaub H, Kastner B, Stark H, Lührmann R. 2024. Structural insights into the cross-exon to cross-intron spliceosome switch. Nature 630: 1012–1019). The pre-B complex is thought to be critical in the regulation of splicing reactions. Its structure suggests how the cross-exon and cross-intron spliceosome assembly pathways converge. The U4, U5, and U6 snRNA backbones are depicted respectively by blue, green, and red ribbons, with bases and Watson-Crick base pairs shown as color-coded blocks: A/A-U in red, C/C-G in yellow, G/G-C in green, U/U-A in cyan; the proteins are represented by gold ribbons. Cover image provided by X3DNA-DSSR, an NIGMS National Resource for structural bioinformatics of nucleic acids (R24GM153869; skmatics.x3dna.org). Image generated using DSSR and PyMOL (Lu XJ. 2020. Nucleic Acids Res 48: e74).

Structure of the Hendra henipavirus (HeV) nucleoprotein (N) protein-RNA double-ring assembly (PDB id: 8C4H; Passchier TC, White JB, Maskell DP, Byrne MJ, Ranson NA, Edwards TA, Barr JN. 2024. The cryoEM structure of the Hendra henipavirus nucleoprotein reveals insights into paramyxoviral nucleocapsid architectures. Sci Rep 14: 14099). The HeV N protein adopts a bi-lobed fold, where the N- and C-terminal globular domains are bisected by an RNA binding cleft. Neighboring N proteins assemble laterally and completely encapsidate the viral genomic and antigenomic RNAs. The two RNAs are depicted by green and red ribbons. The U bases of the poly(U) model are shown as cyan blocks. Proteins are represented as semitransparent gold ribbons. Cover image provided by X3DNA-DSSR, an NIGMS National Resource for structural bioinformatics of nucleic acids (R24GM153869; skmatics.x3dna.org). Image generated using DSSR and PyMOL (Lu XJ. 2020. Nucleic Acids Res 48: e74).

Structure of the helicase and C-terminal domains of Dicer-related helicase-1 (DRH-1) bound to dsRNA (PDB id: 8T5S; Consalvo CD, Aderounmu AM, Donelick HM, Aruscavage PJ, Eckert DM, Shen PS, Bass BL. 2024. Caenorhabditis elegans Dicer acts with the RIG-I-like helicase DRH-1 and RDE-4 to cleave dsRNA. eLife 13: RP93979. Cryo-EM structures of Dicer-1 in complex with DRH-1, RNAi deficient-4 (RDE-4), and dsRNA provide mechanistic insights into how these three proteins cooperate in antiviral defense. The dsRNA backbone is depicted by green and red ribbons. The U-A pairs of the poly(A)·poly(U) model are shown as long rectangular cyan blocks, with minor-groove edges colored white. The ADP ligand is represented by a red block and the protein by a gold ribbon. Cover image provided by X3DNA-DSSR, an NIGMS National Resource for structural bioinformatics of nucleic acids (R24GM153869; skmatics.x3dna.org). Image generated using DSSR and PyMOL (Lu XJ. 2020. Nucleic Acids Res 48: e74).
Moreover, the following 30 [12(2021) + 12(2022) + 6(2023)] cover images of the RNA Journal were generated by the NAKB (nakb.org).
Cover image provided by the Nucleic Acid Database (NDB)/Nucleic Acid Knowledgebase (NAKB; nakb.org). Image generated using DSSR and PyMOL (Lu XJ. 2020. Nucleic Acids Res 48: e74).
By following DSSR citations, I recently noticed a bioRxiv preprint, titled "Assessment of nucleic acid structure prediction in CASP16" by Kretsch et al. The portion where DSSR is mentioned is as follows:
Secondary structures were extracted from CASP16 models with DSSR (v1.9.9-2020feb06). Some models, in particular due to large clashes, failed to run (Supplemental Table 1). The base-pair list was extracted from the table in the output file directly because the dot-bracket structure produced by DSSR, in particular for multimers, can contain errors.
While pleased to see DSSR cited in this significant study, I am concerned about the reported issues and would like to investigate the specific structures and error messages encountered. To better understand the problems and potentially find solutions, I have reached out to the authors for further details. Here is the message I sent initially:
You said DSSR failed to run on some models with large clashes. Could you please share the specific models and the error messages you encountered? I would also be interested in seeing the exact errors you observed in the DSSR-derived DBN for multi-mers. It would be a great opportunity for me to improve DSSR in this area, which would benefit both your group and the broader community. If you are willing to share them, please provide details—preferably on the **public 3DNA Forum**. Don’t hesitate to share openly any bugs or limitations you’ve encountered with DSSR.
The authors responded promptly and provided detailed information about the specific models and error messages encountered. After several
iterations, I successfully resolved the issues and released an updated version of DSSR, namely v2.5.4-2025jun04. You can find the release notes
here. This experience underscores the importance of proactively engaging with the community to enhance the functionality and reliability of a software tool.
In this blog post, I aim to share the specifics of these issues and the steps taken to address them. For ease of reading, I have formatted the response/feedback from the authors in red block quotes, and my enquiries/comments in blue. The beginning round of correspondence is as below.
Do note, the predictors in casp submit some truly atrocious models --- eg 14 atoms all at the exact same x-y-z coordinate. These errors would be with his v1.9.9-2020feb06 install though not your latest version. Would you still like them?
Yes, I would like to see how DSSR behaves with these models. Ideally, it should not crash, but output some warning messages. Only through such testing can we improve the robustness of DSSR. Overall, the more feedback I get, the better.
Buffer overflow bug in DSSR
Most of errors I had with dssr were due to clashes and all zero xyz predictions by predictors, for all of which dssr did not give an error message when dssr failed. There was a case where the prediction looked reasonable but dssr failed with the error message `dssr error*** buffer overflow detected ***`. Please see attached for the 2 pdbs that gave this error.
The two PDB files I received were R1283v3TS294_1o and R1283v3TS294_2o, as listed in Supplementary Table 1: "List of unscored models," with the "Reasons" column indicating a dssr error*** buffer overflow detected ***. I immediately acknowledged receipt of these files, as shown in the following message:
Thank you for sending me the two PDB files which caused DSSR to fail. I can verify the issue and will try to fix the bug ASAP. I'll keep you posted.
Using these data files, I was able to quickly fix the buffer overflow bug. The following is my response to the authors within one day after receiving the files:
With your sample PDB files, I have traced the issue that caused DSSR to fail. The bug was due to a 53-way (`R1283v3TS294_1o`) and 40-way (`R1283v3TS294_2o`) junction loops which are far from the norm. DSSR sets a default limit for the summary line for each loop which is more than sufficient for all normal PDB entries, but falls short for these unusual cases, leading to out of array boundaries. See the attached DSSR output after the bug fix for more details.
This is a clear example where user feedback is crucial for improving the software, which makes it better serve the community.
Zero xyz coordinates and large clashes
After fixing the out-of-bound bug, I also requested other problematic predicted models from the authors, as shown in the following message:
Along the line, please provide the sample PDB files:
- with zero xyz predictions -- I am curious to see what it looks like.
- where the DSSR-derived DBN is problematic for multi-mers
After solving these issues, I will release a new version of DSSR that would make your analysis more straightforward, and benefit other users as well.
The authors responded with the following message:
Thanks for looking into this. Here are some more examples with superimposed structures, large clash, and all zero xyzs in the zip file.
The ZIP file (error_examples.zip) contains three folders (all_zero_xyz, clash and superimposed), each with some problematic models in PDB format. Once again, I promptly acknowledged receipt of the files and was able to reproduce the reported issues.
Garbage in, garbage out. Given these problematic models, one should not expect DSSR to extract any meaningful information from them. Nonetheless, I am committed to enhancing the software so that it can handle such cases more effectively by providing clear error messages and terminating gracefully rather than crashing.
After several days of thinking, elaboration, intensive coding, and testing, I solved the problems. I then communicated the results to the authors in the following detailed message:
Thanks for the sample PDB files (`error_examples`) with all zero XYZ coordinates, large clashes, and superimposed structures. They helped me to understand the issues, think in context, and find solutions. Let's look them one by one:
1. `all_zero_xyz`: These two files `R1211TS159_1` and `R1211TS159_2` have identical contents, except for the MODEL IDs (1 and 2, respectively). Atoms with all-zero XYZ coordinates are a special case of duplicated coordinates. This has led me to implement a check for duplicated coordinates in an input file. The revised DSSR now reports duplicated coordinates and their corresponding atoms, and it quits if the number of duplicated atoms exceeds a certain threshold. For `R1211TS159_1`, the revised DSSR output would be as below:
1 [e] xyz repeated 1904 times:[0.000 0.000 0.000] 1509-P@0.G1 3412-C6@0.C90
[w] no-of-repeats=1 max-freq=1904
...too many duplicates... quit!
2. `clash`: Both files `R1250TS208_1o` and `R1250TS417_1o` contain multiple models, as visible in PyMOL. Each PDB file uses a single MODEL/END pair to include all its models. This setup is akin to an NMR ensemble but without MODEL/ENDMDL delimiters, which leads to clashes when analyzed together. I have revised DSSR to explicitly check for such clashes and terminate execution if too many are detected. Using `R1250TS208_1o` as an example, the DSSR output would be as below:
[i] 0.G1 and 1.G1 in clashes: min_dist=0.57
[i] 0.G1 and 3.G1 in clashes: min_dist=0.35
[i] 0.G1 and 4.G1 in clashes: min_dist=0.41
...too many clashes... quit!
The above list contains only three of the many clashes detected in this file. One can notice immediately the G1 nucleotides from chains `0`, `1`, `3`, and `4` are in clashes (see the attached file `clashes_208.pdb`, which contains only G1 nucleotides from the four chains).
3. `superimposed`: The five example files (`R1283v3TS304_1o` ... `R1283v3TS304_5o`) have similar issues as the clash cases. Running the revised DSSR on `R1283v3TS304_1o` would produce the following output:
[i] 0.A1 and 2.A1 in clashes: min_dist=0.74
[i] 0.A1 and 3.A1 in clashes: min_dist=0.78
[i] 0.A1 and 4.A1 in clashes: min_dist=0.56
...too many clashes... quit!
Here A1 nucleotides from chains `0`, `2`, `3` , and `4` are in clashes (see the attached `superimpose-1.pdb`).
How the `clash` and `superimposed` categories are supposed to be different? They look similar to me.
Overall, the `error_examples` (in `all_zero_xyz`, `clash`, and `superimposed`) pose problems because they do not contain valid DNA/RNA structures as a whole. DSSR cannot extract meaningful information from these files. However, the revised DSSR explicitly highlights these issues, saving users from spending time on invalid data. Do these DSSR revisions make sense to you?
In the end, I am glad to receive the following feedback from the authors:
Thanks, these revisions all make sense! The examples I sent on clashes and superimposed were actually similar and I think the error output makes sense as well.
Final thoughts
This blog post offers an in-depth look at my efforts to enhance DSSR. As the developer of this software product, I am deeply committed to ensuring its quality and usability. I extend my gratitude to the authors for their valuable feedback and assistance in resolving these issues. In return, the updated version of DSSR (v2.5.4-2025jun04) should not only streamline their workflow but also benefit the broader user community.
For those who read through this lengthy post, I want to emphasize that DSSR is actively supported: I am here to listen and help. Any questions related to its use, bug reports, or feature requests are warmly welcomed on the 3DNA Forum. As I’ve mentioned before, please don’t hesitate to share any negative experiences or bugs with DSSR—just ensure to provide specific details so others can reproduce the issue. I will address these concerns as soon as I’m aware of them and will frankly acknowledge any mistakes I may have made. My goal is for DSSR to be a reliable software tool that the community can trust and build upon.
References
Kretsch,R.C. et al. (2025) Assessment of nucleic acid structure prediction in CASP16. bioRxiv; https://doi.org/10.1101/2025.05.06.652459.

In DSSR, the --frame option allows users to reorient a nucleic acid structure using the standard base reference frame (see Olson et al., 2001). This option can be applied not only to an individual base frame but also a base-pair frame, or the middle frame between two bases or base pairs. These variations facilitate the alignment of nucleic acid structures for a wide range of comparative analyses. In this blog post, I will demonstrate how to use the --frame option with concrete examples, enabling readers to apply this unique DSSR feature to their own projects.
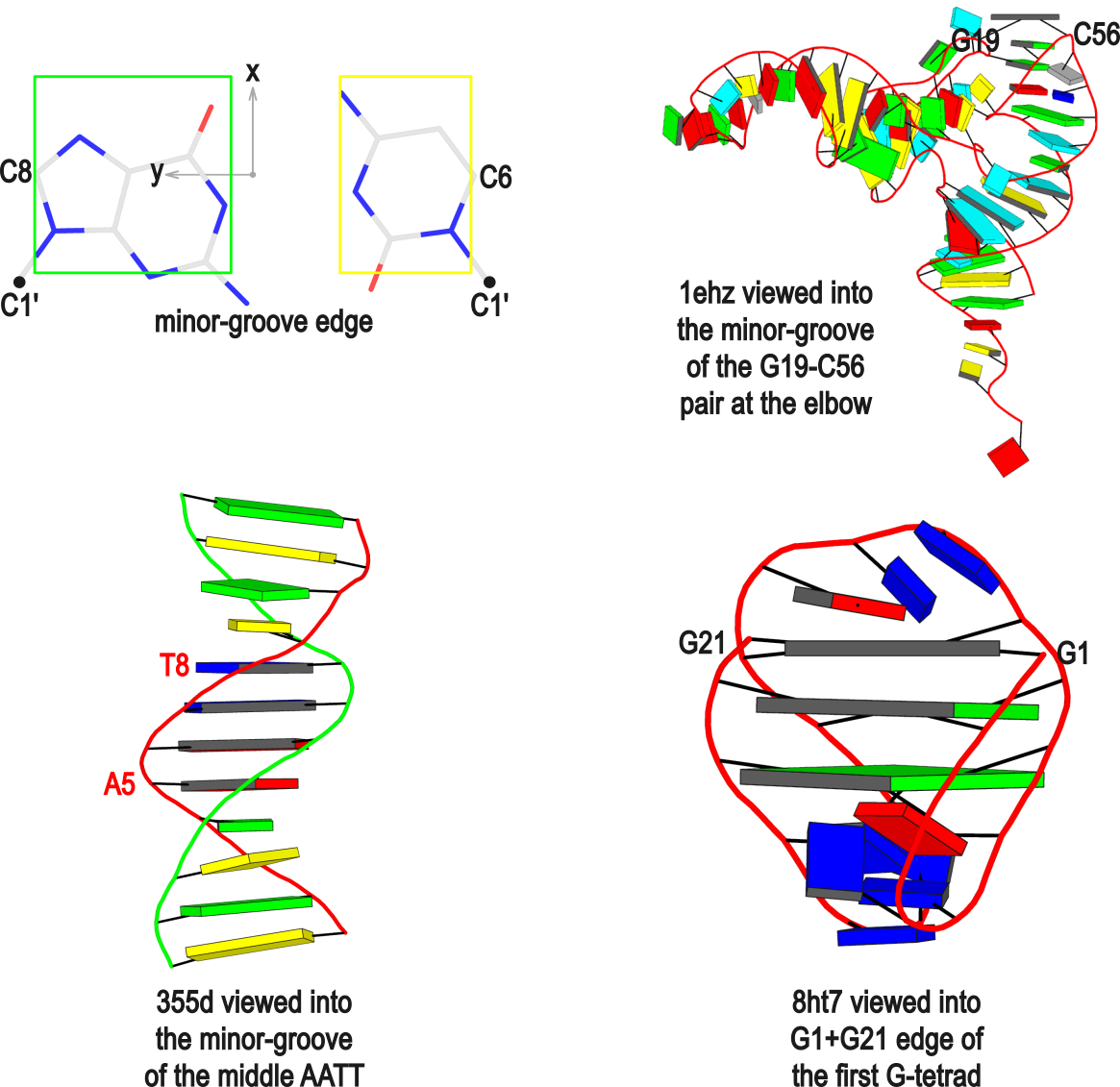
The standard base reference frame
The standard base reference frame is derived from an idealized Watson-Crick base pairing geometry (top-left, figure below). The x-axis points in the direction of the major groove along what would be its pseudo-dyad axis—that is, the perpendicular bisector of the C1'...C1' vector spanning the base pair. The y-axis runs along the long axis of the idealized base-pair in the direction of the sequence strand, parallel to the C1'...C1' vector, and is displaced so as to pass through the intersection between the (pseudo-dyad) x-axis and the vector connecting the pyrimidine Y(C6) and purine R(C8) atoms. The z-axis is defined by the right-handed rule. For right-handed A- and B-DNA, the z-axis accordingly points along the 5' to 3' direction of the sequence strand.
Typical usages of the --frame option
Using the classic B-DNA dodecamer PDB entry 355d as an example, DSSR can be run with the --frame option as follows:
# 1...5..8....
# chain A: 5'-CGCGAATTCGCG -3'
# chain B: 3'-GCGCTTAAGCGC -5'
# reorient 355d in the reference frame of C1 on chain A
x3dna-dssr -i=355d.pdb --frame=A.1 -o=355d-b1.pdb
# reorient 355d in the frame of the Watson-Crick pair C1-G24
x3dna-dssr -i=355d.pdb --frame=A.1:wc -o=355d-bp1.pdb
# ... with the minor-groove of pair C1-G24 facing the viewer
x3dna-dssr -i=355d.pdb --frame=A.1:wc-minor -o=355d-bp1-minor.pdb
# with the minor-groove of the middle AATT tract facing the viewer
x3dna-dssr -i=355d.pdb --frame='A.5:wc-minor A.8:wc' -o=355d-AATT-minor.pdb
# Rendered in cartoon-blocks with base-pair blocks, and black minor-groove
# Load 355d-AATT-minor.pml into PyMOL (bottom-left, figure above)
x3dna-dssr -i=355d-AATT-minor.pdb --cartoon-block --block-file=wc-minor -o=355d-AATT-minor.pml
The abbreviated notation A.1 refers to nucleotide numbered 1 (as indicated in the coordinates file) on chain A. Here, it denotes C1, as shown at the top of the listing. Similarly, A.5 and A.8 correspond to nucleotides A5 and T8 on chain A, respectively. In most cases, such as with 355d, the combination of chain identifier and residue number is sufficient to uniquely identify a nucleotide. More generally, other information such as model number or insertion code may be needed to specify a particular nucleotide.
In the above listing, wc after the colon (for example, A.1:wc) specifies the Watson-Crick base pair that the corresponding nucleotide participates in. Meanwhile, minor transforms the structure so that the minor-groove of the base (or base pair, or step) faces the viewer. The keywords wc and minor are settings that influence the construction or view of the frame. Case or order does not matter for these keywords as long as there is a match—for example, minor+wc works the same as wc-minor.
Two other examples combining the --frame option with cartoon-block representations
The intuitive geometric meaning of the standard base reference frame combined with the DSSR-enabled cartoon-block representation allows for an enhanced understanding of intricate structural features. In the top-right panel of the figure above, we see the classic yeast phenylalanine tRNA (PDB entry 1ehz) viewed into the minor-groove of the pseudo-knotted G19-C56 pair at the elbow of the L-shaped tertiary structure. The stacking interactions of the purines at the top-right of the panel are clearly visible in this view. In the bottom-right panel, an anti-parallel G-quadruplex from PDB entry 8ht7 is shown. The G-tetrads are automatically identified and rendered as square blocks, all with DSSR. This representation makes the chair conformation of the three-layered anti-parallel G-quadruplex crystal clear. The DSSR commands used are listed below:
# yeast tRNA (1ehz)
x3dna-dssr -i=1ehz.pdb --frame=A.19:wc-minor -o=1ehz-elbow.pdb
x3dna-dssr -i=1ehz-elbow.pdb --cartoon-block --block-file=wc-minor -o=1ehz-elbow.pml
# anti-parallel chair-shaped G-quadruplex (8ht7)
x3dna-dssr -i=8ht7.pdb --select=nts -o=8ht7-nts.pdb # extract nucleotides, ignore amino acids
# reorient 8ht7 in the frame of the G-tetrad involving G1, in edge view
x3dna-dssr -i=8ht7-nts.pdb --frame=A.1:G4-minor -o=8ht7-Gtetrad.pdb
x3dna-dssr -i=8ht7-Gtetrad.pdb --block-cartoon --block-file=G4-minor -o=8ht7-Gtetrad.pml
References
Olson,W.K. et al. (2001) A standard reference frame for the description of nucleic acid base-pair geometry. Journal of Molecular Biology, 313, 229–237.
The 3DNA suite includes the mutate_bases program, which, as its name suggests, mutates bases while maintaining the backbone conformation. This feature was incorporated into the suite following user feedback and has been utilized in several studies before being formally published in the Li et al. (2019) paper. A key advantage is that the mutation process preserves both the geometry of the sugar-phosphate backbone and the base reference frame, encompassing position and orientation. Consequently, re-analyzing the mutated model yields identical base-pair and step
parameters as those of the original structure.
In DSSR, the standalone mutate_bases program has become the mutate sub-command with enhanced functionality and improved usability, as documented in the User Manual. The mutate module allows users to perform base mutations efficiently and effectively by taking advantage of the powerful DSSR analysis engine.
To further expand the modeling capabilities of the DSSR, v2.5.3 introduced the --mutate-type option to allow for backbone mutations, based on the base reference frame. Furthermore, the target can be any fragment, regardless of length or composition, rather than just a single nucleotide. When combined with the rebuild module, this feature significantly enhances DSSR’s ability to model nucleic acid structures.
Here is an example of modeling PDB entry 1msy, a 27-nt structure (1msy.pdb) that mimics the sarcin/ricin loop from E. coli 23S ribosomal RNA.
x3dna-dssr analyze -i=1msy.pdb --ss --rebuild -o=1msy-expt.out
mv dssr-ssStepPars.txt 1msy-step.txt
x3dna-dssr rebuild --backbone=RNA --par-file=1msy-step.txt -o=1msy-step.pdb
x3dna-dssr -i=1msy.pdb --select-resi='A 2654' -o=1msy-A2654.pdb
x3dna-dssr -i=1msy.pdb --select-resi='A 2655' -o=1msy-G2655.pdb
x3dna-dssr -i=1msy-A2654.pdb --frame=2654 -o=frame___A.pdb
x3dna-dssr -i=1msy-G2655.pdb --frame=2655 -o=frame___G.pdb
x3dna-dssr mutate -i=1msy-step.pdb --entry='num=8 to=A; num=9 to=G' -o=1msy-C2endo.pdb --mutate-part=whole
x3dna-dssr --connect-file -i=1msy-C2endo.pdb -o=1msy-C2endo-cnt.pdb --po-bond=5.0
- The
analyze step uses options --ss and --rebuild to generate the file dssr-ssStepPars.txt (containing base-step parameters), which is then renamed to 1msy-step.txt. The rebuild step employs 1msy-step.txt to construct a structure (1msy-step.pdb) with regular C3'-endo sugar RNA backbone conformation. Note that the rebuilt structure has nucleotides numbered from 1 to 27, while in the PDB 1msy, they correspond to 2647 to 2673, respectively.
- However, the A2654 and G2655 dinucleotides in 1msy are actually in C2'-endo sugar conformation, creating the S-shaped structure around the GpU platform. The above rebuilt structure does not reflect this distortion. So we extract A2654 and G2655 with
--select-resi and then put each in its standard base reference frame, named frame___A.pdb and frame___G.pdb, respectively.
- Now we mutate A8 and G9 in the rebuilt structure
1msy-step.pdb to A and G with option --mutate-part=backbone to ensure the backbone conformations are changed according to those in frame___A.pdb and frame___G.pdb, respectively. The resulting structure is named 1msy-C2endo.pdb. Now the S-shape around the GpU platform is preserved, even though the backbone are not always covalently connected, due to large O3'(i-1) to P(i) distances between neighboring nucleotides. The last step is to generate CONECT records with --connect-file option to connect the backbone atoms explicitly, resulting in more smooth backbone cartoon representation in PyMOL as shown below.
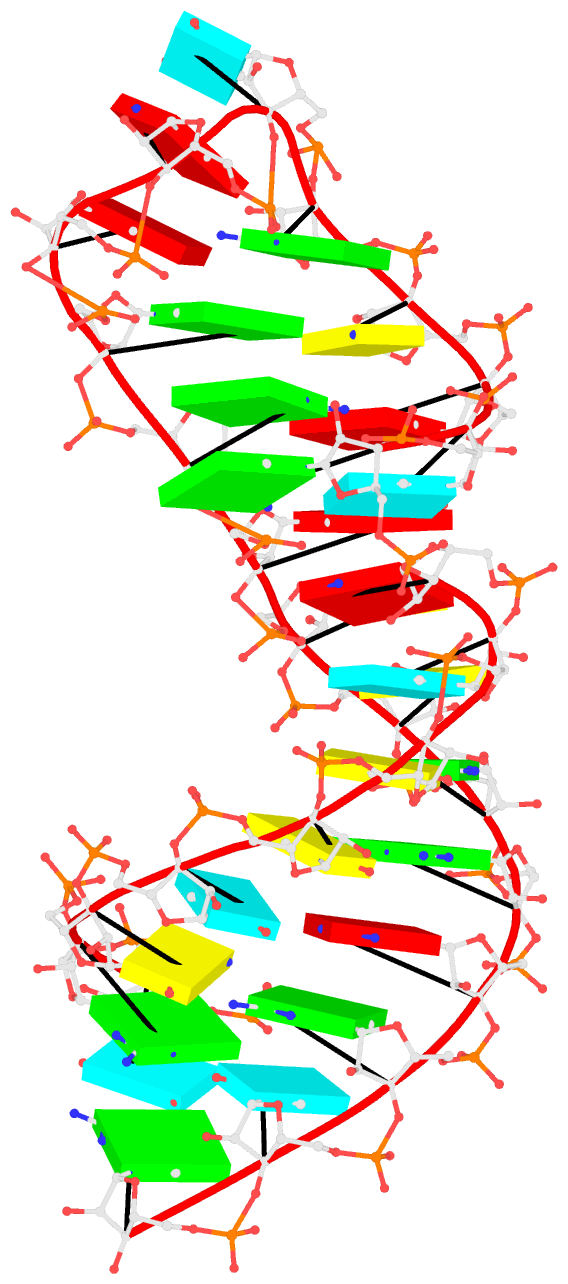
As noted in the Li et al. (2019) paper, users can optimize this approximate backbone connection using Phenix, while keeping the base atoms fixed. The 3DNA-Phenix combination leads to a model where the base geometry strictly follows the parameters prescribed in the user-specified file, and the backbone is regularized with improved stereochemistry and a ‘smooth’ appearance in ribbon representation.
There are other variants of the DSSR mutate module, including for building Z-DNA backbones. However, the above example is sufficient to demonstrate the power of the integrated approach enabled by DSSR for the analysis and modeling of nucleic acid structures. See the DSSR User Manual for more details.
References
Li,S. et al. (2019) Web 3DNA 2.0 for the analysis, visualization, and modeling of 3D nucleic acid structures. Nucleic Acids Res., 47, W26–W34.
Recently, I read carefully the two papers by Farag et al. on the ASC-G4 algorithm to calculate "advanced structural characteristics of G-quadruplexes" (2023), and the comprehensive analysis results of intramolecular G4 structures in the PDB (2024). By developing a convention to orient and number the four strands, ASC-G4 allows for unambiguous determination of the intramolecular G4 topology. It also has an in-depth discussion on assigning syn or anti glycosidic configuration of guanosines, and categorizes four different types of snapbacks.
I am glad to see that DSSR is cited in these two papers, as quoted below:
X3dna-DSSR (19) (http://x3dna.org) is a website that was created to calculate nucleic acid structural parameters, like the local base-pair parameters, local step base-pair parameters, torsion angles, etc, but not the special characteristics of G4. A subdomain dedicated to G4, DSSR-G4DB (Dissecting the Spatial Structure of RNA – G4 Data Base) (http://g4.x3dna.org) emanated from this website. It is a database that gathers and calculates some specific structural information about published G4s, like the topology, the rise, the helical twist, etc, but not the groove widths or the presence of snapbacks. -- Farag et al. (2023)
Indeed, DSSR-G4DB dose not classify snapbacks. I was aware of such non-canonical G4s when I first developed the G4 module in DSSR around 2017-2018, and the V-shaped loops was derived to reflect the peculiarity of snapbacks.
DSSR classifies groove widths as medium, wide, or narrow, based on the glycosidic angles of neighboring guanosines in a G-tetrad, following the G4 literature. Using PDB entry 2lod as an example, the relevant part of the DSSR output is shown below. The groove widths of the three G-tetrads in the G4-stem have the same pattern of groove=--wn, standing for medium, medium, wide, and narrow, respectively. Note that the medium groove is represented by a dash instead of m because --wn stands out more clearly than mmwn (similar idea applies to glycosidic bond, e.g., sss-).
1 glyco-bond=sss- sugar=---- groove=--wn Major-->WC N- nts=4 GGGG A.DG1,A.DG6,A.DG20,A.DG16
2 glyco-bond=---s sugar=---- groove=--wn WC-->Major N+ nts=4 GGGG A.DG2,A.DG7,A.DG21,A.DG15
3 glyco-bond=---s sugar=---- groove=--wn WC-->Major N+ nts=4 GGGG A.DG3,A.DG8,A.DG22,A.DG14
Since DSSR-G4DB is a database, the user cannot provide his own G4 structure, to obtain structural information. Hence the necessity of developing a website where the user uploads his G4 structure file to obtain all its important and specific structural characteristics (like the topology, the groove width, the tilt and twist angles, etc.). This can be very useful, not only for the analysis of published PDB structures but also for structures in refinement or obtained from MD simulations, to evaluate their quality. To our knowledge, there is no website dedicated to G4 to do such calculations in real-time. Therefore, we developed the algorithm ASC-G4 (advanced structural characteristics of G4) and deployed it as a user-friendly website at the following address: http://tiny.cc/ASC-G4. -- Farag et al. (2023)
Thanks to the NIH R24GM153869 grant support, the http://g4.x3dna.org website now allows users to upload their own atomic structures in PDB for mmCIF format for the identification, annotation, and visualization of G4s. See the example of uploading PDB coordinate file 2lod.pdb.
As background, I had long aspired to develop a dynamic website for on-demand G4 structural analysis but was unable to pursue this goal until recently. During the 4-year funding gap, I still managed to maintain the website g4.x3dna.org, which provides DSSR results for G4 structures in the PDB (a resource now known as the DSSR-G4DB database). To date, the only published work related to G4s is my 2020 paper on the integration of DSSR with PyMOL. Clearly, a dedicated method paper detailing the G4 module in DSSR and the g4.x3dna.org website has been long overdue.
As an initial step toward addressing this gap, I have recently revised the G4-related code in DSSR, fixed existing bugs, and added new features. The g4.x3dna.org website has undergone a complete overhaul, enabling users to upload their own structures for dynamic G4 analysis. Additionally, the DSSR-G4DB database is being actively updated on a weekly basis as new PDB entries are added.
Calculation of the twist and tilt angles. In G4, the helix twist is the rotation of a tetrad relative to its successive one. To measure the twist angle, the most spread method is that described by Lu and Olson (2003) (32) and Reshetnikov et al. (2010) (33). In this method, the angle is calculated from the dot product between two C1’–C1’ vectors from two successive tetrads, i and i + 1, the C1’ atoms of each vector belonging to two adjacent guanosines of a Hbp. The issue with this method is that it does not allow access to the sign of the angle, which defines the direction of the G4 helix, viz. right-handed or left-handed. -- Farag et al. (2023)
There is clearly a misunderstanding in the above text. 3DNA/DSSR can handle left-handed Z-DNA without any issues. DSSR also reports negative twist angles for left-handed G4s, as shown clearly for PDB entry 7d5e, for example.
3DNA/DSSR derives a complete of set of six base-pair parameters (including shear and opening), six step parameters (including twist and rise), and six helical parameters, using a rigorously defined and completely reversible algorithm (CEHS) and the standard base-reference frame. See section "3.2.3 Base pairs" in DSSR User Manual for more details. The DSSR output for G4s (as in DSSR-G4DB) reports only twist and rise, along with overlapped areas, simply because these are the most important parameters and easily interpretable.
The list of the resolved G4 structures was downloaded from the ONQUADRO website (https://onquadro.cs.put.poznan.pl/) (39) at about the end of October 2023. It consisted of 291 intramolecular structures (named unimolecular in the website) and 154 intermolecular G4s (96 bimolecular and 58 tetramolecular). Only the intramolecular structures were kept for this study. To this list, we added 55 missing intramolecular structures that were found on the website of DSSR-G4DB (http://g4.x3dna.org) (40). From the merged list, 345 structures were downloaded from the Protein Data Bank (PDB) (http://www.rscb.org/pdb/) (41) because one structure had no available coordinates in the PDB format (7ZJ5 (42)). -- Farag and Mouawad (2024)
DSSR adopts the frame of reference of Webba da Silva, designating the four strands and grooves of G4-stem as shown below using PDB entries 8ht7 (G1 in syc) and 5ua3 (G1 in anti) as example for the syn or anti glycosidic bond of the 5'-guanosine, respectively.
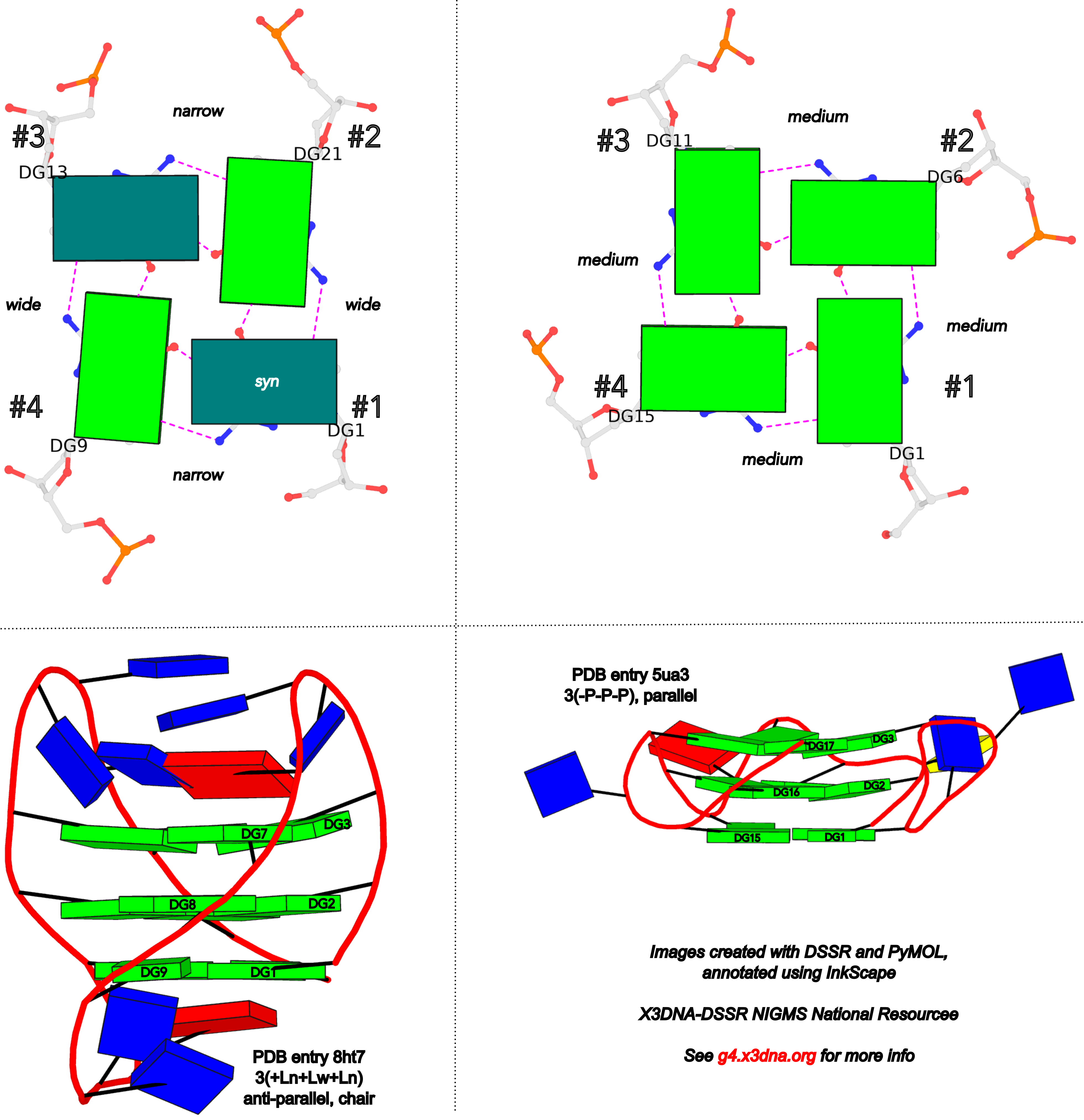
In DSSR, the first strand (#1) is always upward (U) from 5' to 3'-end, and the polarity of the other three strands is determined by its orientation relative to #1: U if parallel, or D if antiparallel. There are a total of 2x2x2=8 possible combinations of U and D for the three strands, which define parallel (U4: UUUU), antiparallel (U2D2: UDDU, UDUD, UUDD), or hybrid (UD3: UDDD; U3D: UDUU, UUDU, UUUD). For example, the PDB entry 2lod is characterized by DSSR as: "hybrid-(mixed), UUUD, U3D(3+1)", and PDB entry 8ht7 as: "anti-parallel, UDUD, chair(2+2)". This notation is topologically equivalent to the one adopted by ASC-G4 but with opposite orientation of the strands.
Overall, DSSR and ASC-G4 provide different perspectives on G4 structures. It is to the user to decide which one is more suitable for their needs.
References
Farag,M. et al. (2023) ASC-G4, an algorithm to calculate advanced structural characteristics of G-quadruplexes. Nucleic Acids Res., 51, 2087–2107.
Farag,M. and Mouawad,L. (2024) Comprehensive analysis of intramolecular G-quadruplex structures: furthering the understanding of their formalism. Nucleic Acids Res., gkae182.
In late September of 2018, I contacted Dr. Mateus Webba da Silva requesting a copy of his 2007 article, titled "Geometric formalism for DNA quadruplex folding". At that time, I had implemented a G4 module within DSSR for the automatic identification, comprehensive annotation, and schematic visualization of G-quadruplexes from 3D atomic coordinates. I noticed the 2007 paper, and was intrigued by the following sentences in the abstract:
A formalism is presented describing the interdependency of a set of structural descriptors as a geometric basis for folding of unimolecular quadruplex topologies. It represents a standard for interpretation of structural characteristics of quadruplexes, and is comprehensive in explicitly harmonizing the results of published literature with a unified language.
Mateus kindly sent me a copy of the 2007 article, and shortly afterwards he also shared with me the Dvorkin et al. (2018) paper on "Encoding canonical DNA quadruplex structure". I carefully read both papers, plus the Karsisiotis et al. (2013) tutorial paper. I was impressed by the elegance of the formalism: simple and systematic, so I immediately decided to add this feature to the G4 module of DSSR.
As the Chinese saying goes, "纸上得来终觉浅,绝知此事要躬行" ("What you learn from books is always shallow. You must practice it yourself to know it well." -- Google Translate). The implementation process was challenging because of subtleties in the formalism, but very rewarding. It is all about scientific understanding and software engineering. Only after a thorough understanding and attention to meticulous details can one create a robust and reliable software tool. On the other hand, once properly implemented, the DSSR G4 module can be applied consistently. Any discrepancies between DSSR output and literature merit further investigation. These discrepancies could either arise from bugs in DSSR (which I will promptly address upon identification) or, more likely, typos or errors in the reported results.
Webba da Silva (2007) systematically described the interdependency of glycosidic bond (syn or anti), strand polarity (parallel or anti-parallel), groove width (narrow, medium, or wide), and loop type (lateral, propeller, or diagonal) in unimolecular G-quadruplexes. Figures 1-3 and Scheme 1 of Webba da Silva (2007) are very informative, and easy to follow conceptually. The Karsisiotis et al. (2013) tutorial provided further details based on experimentally determined G-quadruplex structures from the PDB (e.g., Figure 3: the schematic for all possible combinations of glycosidic bond and the corresponding groove-width combinations in G-tetrad). Some key observations:
- Since glycosidic bond can be either syn or anti, there a total of
2x2x2x2 = 16 possible combinations in a G-tetrad.
- The disposition of glycosidic bond of guanosines in a G-tetrad leads to only eight possible groove-width combinations.
- Only tetrads with the same groove-width combinations may stack to form stable G-quadruplexes.
- Propeller loops invariably link medium grooves within a G-quadruplex stem.
- Lateral and diagonal loops bridge guanosines of different glycosidic bond.
- If a single-stranded quadruplex starts with a narrow groove, it can only be with a clockwise loop progression (i.e., +lateral).
- There are 26 permissible looping combinations within a canonical unimolecular G-quadruplex (G4-stem).
To unambiguously characterize a G4-stem, Webba da Silva (2007) defined a frame of reference where the 5’-G in a G4-stem is set as the origin, and the first strand is progressing towards the viewer. Regardless of the clockwise or anti-clockwise progression of the base sequence, the scheme designates one orientation for the syn and anti glycosidic bond by following G+G H-bonding alignments. Put another way, grooves and strands are strictly related to the reference (first) strand in an anti-clockwise manner, irrespective of the progression of the base sequence. The point is illustrated in the figure below, using PDB entries 8ht7 (G1 in syc) and 5ua3 (G1 in anti) as an example for the syn or anti glycosidic bond of the 5'-guanosine, respectively.
Based on previous work, the Dvorkin et al. (2018) paper proposed a systematic nomenclature for G4-stem. The single structural descriptor contains:
- The number of G-tetrads (i.e., the G-tract length).
- Loop types (lowercase l for lateral, p for propeller, and d for diagonal) and relative direction ("+" for clockwise and "-" for anti-clockwise progression, using the frame of reference described above).
- For lateral loops, the groove widths ("w" for wide, and “n” for narrow) are denoted in subscript.
So a complete descriptor could be 2(+lnd−p), as shown in Figure 1A of the Dvorkin et al. (2018) paper. Significantly, Figure 1B therein further gave structural descriptors for six experimentally determined G4-stems from the PDB. These examples, plus the ones in the supplementary materials, were used to validate my implementation of the systematic nomenclature in the G4 module of DSSR. My results agree with those in the Dvorkin et al. (2018) paper, except for two cases, which are discussed below.
- For PDB entry 2gku: 3(-p-ln-lw) (Dvorkin et al.) vs 3(-P-Lw-Ln) (DSSR), with swapped n (narrow) and w (wide) groove widths for both lateral loops.
- For PDB entry 2lod: 3(-pd+ln) (Dvorkin et al.) vs 3(-PD+Lw) (DSSR), with swapped n (narrow) and w (wide) groove width for the lateral loop.
Note that in DSSR, I am using uppercase L/P/D for lateral/propeller/diagonal loop types, and lowercase n/w for narrow/wide groove widths, respectively. Doing so distinguishes between the different loop types and groove widths in pure text format.
After careful examination of these discrepancies, I still couldn’t find any errors in my implementation. So I contacted Mateus for verification (in early October 2018). Thankfully, he quickly responded and acknowledged the mistakes for PDB entry 2gku in Dvorkin et al. (2018), saying "There can not be a –Ln after the –p." Clearly, the wrong descriptor for PDB entry 2gku in Dvorkin et al. (2018) was due to a typographical error. This example illustrates the power of a robust software tool like DSSR.
References
Dvorkin,S.A. et al. (2018) Encoding canonical DNA quadruplex structure. Sci. Adv., 4, eaat3007.
Karsisiotis,A.I. et al. (2013) DNA quadruplex folding formalism – A tutorial on quadruplex topologies. Methods, 64, 28–35.
Webba da Silva,M. (2007) Geometric formalism for DNA quadruplex folding. Chemistry A European J, 13, 9738–9745.
Over the past few years, the Szachniuk group has made several significant contributions to the field of structural bioinformatics of G-quadruplexes. The following five publications are particularly noteworthy, and I am glad to see that 3DNA/DSSR have been cited in all of them.
1. Zok et al. (2020) -- ElTetrado: a tool for identification and classification of tetrads and quadruplexes
The BMC Bioinformatics paper introduced the ElTetrado software tool for identifying and classifying G-tetrads in unimolecular G-quadruplex structures into ONZ taxonomy. Here DSSR is employed to identify base-pairs and base-stacking interactions.
ElTetrado processes PDB and mmCIF files to identify quadruplexes and their component tetrads in nucleic acid structures (Fig. 2). It applies DSSR [24] to collect the preliminary information about base pairs and stacking.
We recommend that, apart from ElTetrado, the users should download the DSSR binary [24] and place it in the same local directory. DSSR is utilized for the preliminary analysis of base pairs in the input 3D structure. Its local installation allows the users to control DSSR execution. For example, one can decide to pass --symmetry parameter to x3dna-dssr binary when dealing with X-ray structures, which is necessary for some quadruplexes.
As documented in the DSSR Manual, by default, DSSR reads in the first model of an NMR ensemble. A biological unit of X-ray crystal structures in the PDB may contain symmetry-related components formatted as a MODEL/ENDMDL delimited, NMR-like ensemble. In such cases, the --symmetry (or --symm) option is required for DSSR to process the entire biological unit.
For example, x3dna-dssr -i=4ms9.pdb1 --symm leads to the identification of 10 Watson-Crick base pairs in the biological unit of PDB entry 4ms9 (uploaded). The --symm option is now enabled for user-uploaded PDB files on the skmatic.x3dna.org website. Without the --symm option, DSSR would not find any Watson-Crick base pairs in 4ms9.pdb1 since MODEL#1 is single stranded.
Noticing the confusion users may have in using the --symm option, I have revised DSSR to check for overlapped residues. When all models in an NMR ensemble are taken as a whole with the --symm option, there will be overlapped residues. In such cases, DSSR will report a diagnostic message and proceed with the first model only. The final result is as if --symm has not been specified. Put another way, specifying --symm for an NMR ensemble does no harm to the analysis. For example, analyzing PDB entry 8xeq with the --symm option would have the following message and only the first model would be processed.
x3dna-dssr -i=8xeq.pdb --symm -o=8xeq.out
[i] You specified --symm, but the input file is an (NMR) ensemble
*** in the following, only the FIRST model will be processed ***
Alternatively, if the users do not want to have a local version of DSSR binary, they can obtain the DSSR output in JSON format from any place and use them as input data for ElTetrado (with --dssr-json parameter).
ElTetrado is started from the command line. The users enter the program name and either --pdb followed by an input file name (the file should be in PDB or mmCIF format), or --dssr-json followed by a path to JSON file generated by DSSR, or both switches at once.
The JSON output from DSSR can be obtained directly from the skmatic.x3dna.org website for pre-processed PDB entries or user-supplied coordinate files. For examples, for PDB entry 1ehz, the URL is http://skmatic.x3dna.org/pdb/1ehz/1ehz.json. Alternatively, users can use the web API to get the JSON file, as shown below:
# Pre-processed PDB entry:
curl http://skmatic.x3dna.org/api/pdb/1ehz/json
# With user-supplied PDB file
curl http://skmatic.x3dna.org/api -F 'model=@1ehz.pdb' -F 'type=json'
curl http://skmatic.x3dna.org/api -F 'url=https://files.rcsb.org/download/1ehz.pdb.gz' -F 'type=json'
2. Popenda et al. (2020) -- Topology-based classification of tetrads and quadruplex structures
This paper presents the ONZ scheme to clarify tetrads in unimolecular structures (see Figure 2 therein). Note that DSSR, with option --G4=ONZ, classifies G-tetrads into ONZ taxonomy. For example, the PDB entry 2gku has one G-tetrad (G3, G9, G17, G21) in the O- category, and two G-tetrads in O+.
Structures from both sets were analyzed using self-implemented programs along with DSSR software from the 3DNA suite (Lu et al., 2015). From DSSR, we acquired the information about base pairs and stacking.
3. Zurkowski et al. (2022) -- DrawTetrado to create layer diagrams of G4 structures
DrawTetrado generates static layer diagrams that represent structural data in a pseudo-3D perspective. The layer diagram is very informative and visually pleasing, and it complements the cartoon block schematics generated by the DSSR-PyMOL integration and the detailed DSSR characterization of G-quadruplexes.
So far, the only visual model designed for the 3D structure of quadruplexes is cartoon block schematics (Fig. 1C). These models are generated by DSSR-PyMOL integration and presented as static images of the structure viewed from six perspectives (Lu, 2020).
4. Adamczyk et al. (2023) -- WebTetrado: a webserver to explore quadruplexes in nucleic acid 3D structures
The topologies underlying the classification of quadruplexes and other parameters of their structures can be analyzed using a few computational tools. DSSR (7) was the first to target the detection of G-quadruplexes in 3D structure data saved in PDB and PDBx/mmCIF files and to describe their features. It runs systematically on all entries in the Protein Data Bank and collects motifs found in the DSSR-G4DB database. ElTetrado (8) can identify and analyze G4s and other kinds of tetrads and quadruplexes, classify them, and compute their parameters. It is the core of the computation pipeline running within the ONQUADRO database system (9). The most recent tool for processing atom coordinates in the search for quadruplexes is ASC-G4 (10). It calculates more features than DSSR and ElTetrado, but is limited to unimolecular quadruplexes and supports only the PDB format.
The example illustration in Figure 3 of the paper is on PDB entry 6h1k, the major G-quadruplex form of HIV-1 LTR (long terminal repeat). The layer diagram shown below, re-generated using the WebTetrado website, helps visualize the detailed characterization of DSSR very nicely.
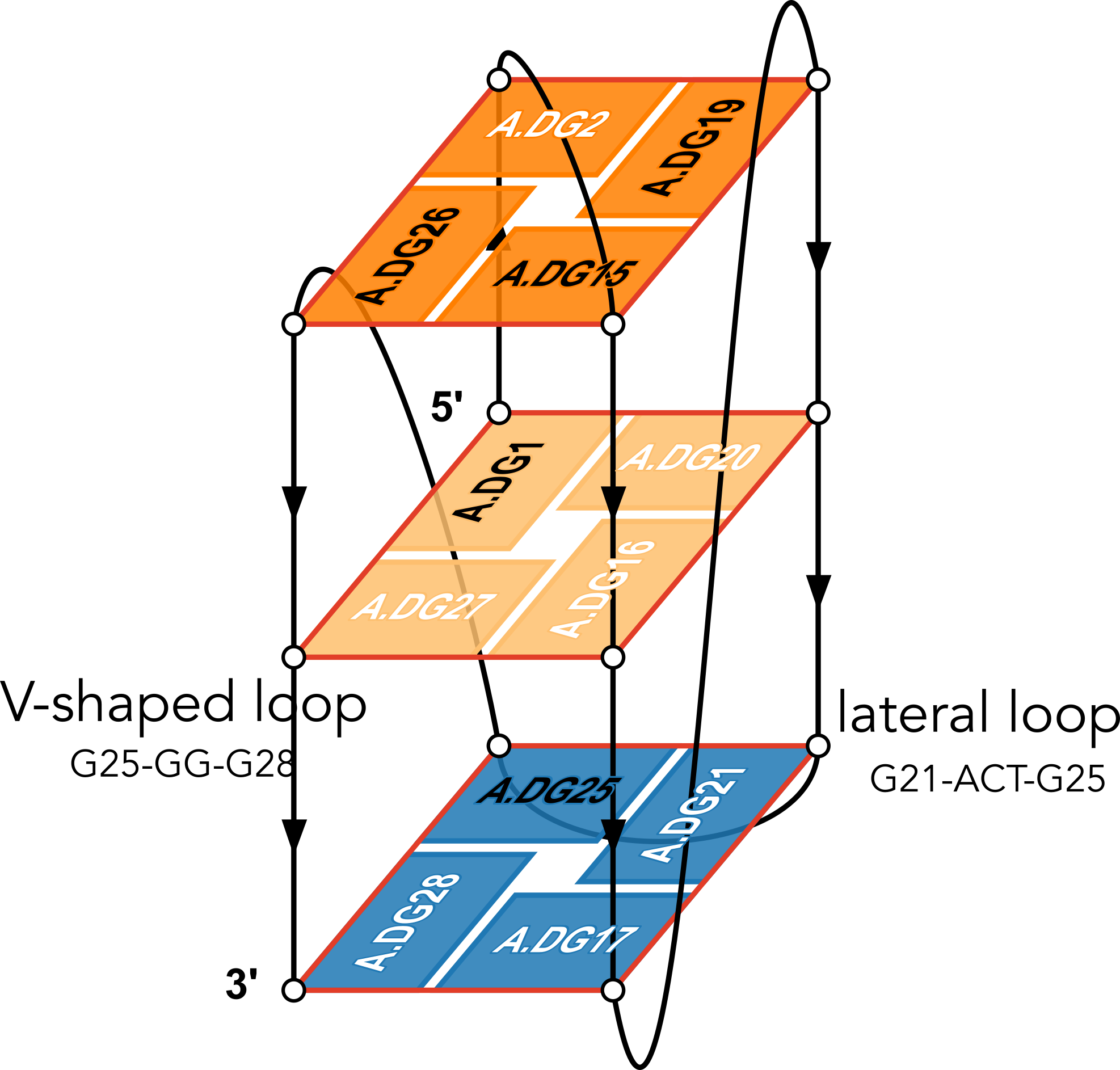 "In DSSR, a G4-helix is defined by stacking interactions of G-tetrads, regardless of backbone connectivity, and may contain more than one G4-stem." For PDB entry 6h1k, DSSR identifies a G-helix with three G-tetrads, ordered properly. Specifically, strand#1 consists of (G2, G1, and G25), even G1 and G25 are not covalently connected. On the other hand, "In DSSR, a G4-stem is defined as a G4-helix with backbone connectivity. Bulges are also allowed along each of the four strands." Thus, the G4-stem is composed of only two G-tetrads, as detailed below.
"In DSSR, a G4-helix is defined by stacking interactions of G-tetrads, regardless of backbone connectivity, and may contain more than one G4-stem." For PDB entry 6h1k, DSSR identifies a G-helix with three G-tetrads, ordered properly. Specifically, strand#1 consists of (G2, G1, and G25), even G1 and G25 are not covalently connected. On the other hand, "In DSSR, a G4-stem is defined as a G4-helix with backbone connectivity. Bulges are also allowed along each of the four strands." Thus, the G4-stem is composed of only two G-tetrads, as detailed below.
Stem#1, 2 G-tetrads, 3 loops, INTRA-molecular, UDDD, hybrid-(mixed), 2(D+PX), UD3(1+3)
1 glyco-bond=s--- sugar=---- groove=w--n Major-->WC Z- nts=4 GGGG A.DG1,A.DG20,A.DG16,A.DG27
2 glyco-bond=-sss sugar=.-.3 groove=w--n WC-->Major Z+ nts=4 GGGG A.DG2,A.DG19,A.DG15,A.DG26
step#1 mm(<>,outward) area=12.76 rise=3.47 twist=18.2
strand#1 U DNA glyco-bond=s- sugar=-. nts=2 GG A.DG1,A.DG2
strand#2 D DNA glyco-bond=-s sugar=-- nts=2 GG A.DG20,A.DG19
strand#3 D DNA glyco-bond=-s sugar=-. nts=2 GG A.DG16,A.DG15
strand#4 D DNA glyco-bond=-s sugar=-3 nts=2 GG A.DG27,A.DG26
loop#1 type=diagonal strands=[#1,#3] nts=12 GAGGCGTGGCCT A.DG3,A.DA4,A.DG5,A.DG6,A.DC7,A.DG8,A.DT9,A.DG10,A.DG11,A.DC12,A.DC13,A.DT14
loop#2 type=propeller strands=[#3,#2] nts=2 GC A.DG17,A.DC18
loop#3 type=diag-prop strands=[#2,#4] nts=5 GACTG A.DG21,A.DA22,A.DC23,A.DT24,A.DG25
List of 2 non-stem G4-loops (including the two closing Gs)
1 type=lateral helix=#1 nts=5 GACTG A.DG21,A.DA22,A.DC23,A.DT24,A.DG25
2 type=V-shaped helix=#1 nts=4 GGGG A.DG25,A.DG26,A.DG27,A.DG28
DSSR correctly identifies the 12-nt diagonal loop, containing a canonical duplex stem and a hairpin loop. Notably, the G-tetrad (25-21-17-28) does not belong to the G4-stem because of the broken backbone connectivity between G1 and G25. Instead, the Gs in the G-tetrad (25-21-17-28) become part of the following two loops, which are certainly unconventional yet follow naturally the DSSR definition of G4-stem.
- The propeller loop, which now includes G17 (part of the G-tetrad), in addition to C18.
- The unusual diag-prop (diagonal-propeller ) loop, which consists of G21, A22, C23, T24, and G25.
Moreover, DSSR also reports two loops that are not defined by the G4-stem: the V-shaped loop (G25-G26-G27-G28) and the lateral loop (G21-A22-C23-T24-G25). See the notes in the above layer diagram. V-shaped loop occurs when the 5’-endmost G-tetrad lies in the middle of the G-quartets stack as in the non-canonical G4 structures with snapbacks.
The G4-helix and G4-stem definitions parallel those for duplex helix and stem in DSSR. The characterization of loops follows naturally once G4-stem or duplex stem are identified. The unusual propeller and diagonal-propeller loops noted above are due to non-canonical structures, which also lead to the listing of non-stem G4-loops.
I may consider to add special handling of snapbacks (or other worthwhile classes of non-canonical G4 structures) so that the reported loops follow whatever consensus the community agrees upon in the future. Nevertheless, I would like to emphasize that the consistent definitions of G4-stem and loops in DSSR help pinpoint extraordinary features to draw users' attention to non-canonical G4 structures. The layer diagram from DrawTetrado and WebTetrado are very handy in illuminating the basic concept and technical details, as shown here for PDB entry 6h1k.
5. Zok et al. (2022) -- ONQUADRO: a database of experimentally determined quadruplex structures
The computational engine is composed of scripts utilising in-house and third-party procedures, responsible for data collection, quadruplex identification, computation of structure parameters, secondary structure annotation, visualisation of the secondary and tertiary structure models, database queries, generation of statistics, and newsletter preparation. DSSR (--pair-only mode) (36) and ElTetrado (39) functionalities are applied to identify quadruplexes, tetrads, and G4-helices in nucleic acid structures.
References
Adamczyk, B., Zurkowski, M., Szachniuk, M., & Zok, T. (2023). WebTetrado: a webserver to explore quadruplexes in nucleic acid 3D structures. Nucleic Acids Research, 51(W1), W607–W612. https://doi.org/10.1093/nar/gkad346
Popenda, M., Miskiewicz, J., Sarzynska, J., Zok, T., & Szachniuk, M. (2020). Topology-based classification of tetrads and quadruplex structures. Bioinformatics, 36(4), 1129–1134. https://doi.org/10.1093/bioinformatics/btz738
Zok, T., Kraszewska, N., Miskiewicz, J., Pielacinska, P., Zurkowski, M., & Szachniuk, M. (2022). ONQUADRO: a database of experimentally determined quadruplex structures. Nucleic Acids Research, 50(D1), D253–D258. https://doi.org/10.1093/nar/gkab1118
Zok, T., Popenda, M., & Szachniuk, M. (2020). ElTetrado: a tool for identification and classification of tetrads and quadruplexes. BMC Bioinformatics, 21(1), 40. https://doi.org/10.1186/s12859-020-3385-1
Zurkowski, M., Zok, T., & Szachniuk, M. (2022). DrawTetrado to create layer diagrams of G4 structures. Bioinformatics, 38(15), 3835–3836. https://doi.org/10.1093/bioinformatics/btac394
I recently came across the Direk & Doluca (2024) paper on CIIS‐GQ: Computational Identification and Illustrative Standard for representation of unimolecular G‐Quadruplex secondary structures. Since DSSR is mentioned extensively in this work, with a section comparing CIIS-GQ and DSSR in supplementary materials, it is worthwhile to explore the issues raised in the paper. Overall, following literature allows me to clarify misconceptions and fix bugs that further improve DSSR.
The data which contain the G-quadruplexes were identified by DSSR-G4DB website [12, 13, 16]. All of the PDB (protein data bank) ids of DNA and RNA structures are extracted from the aforementioned website and the pdb files which contain the three dimensional data of the corresponding structures were downloaded from the protein data bank [3–5]. [under section "Materials and Methods": "Data"]
The DNA and RNA structures listed in 3DNA website were identified and downloaded from Protein Data Bank. Only unimolecular structures were used for the rest of the study (Supplementary Fig. 2). [under section "Results"]
Additionally, DSSR requires licensing to get annotation results for G-quadruplex structures. Fortunately, the annotation results for a number of G-quadruplexes were already published at DSSR-G4DB (46) and we were able to compare. [under section "Comparison with DSSR" in supplemental materials]
I am glad the DSSR-G4DB website served as a starting point for this study. The G4.x3dna.org website, where DSSR-G4DB is hosted, has always been available to the public. With the NIH R24GM153869 grant support, the standalone DSSR software is free for academic use and can be obtained from the Columbia Technology Ventures (CTV) website.
All obtained results for each pdb file were compared with DSSR. Out of which 35 DNA and 13 RNA structures were analyzed differently (Supplementary Table 2). Significant differences were detected for a number of structures between CIIS-GQ and DSSR analysis. For example, in 1k8p, 3ibk, 6ip7 and 5ccw structures, DSSR fails to identify some loops in some structures.
Most common issue that we have observed with DSSR is that it places loops in wrong places in some structures. For example, In 2a5p structure, the first loop is identified as reversal by both tools but DSSR also assigns the G6 to this loop which already participates in a tetrad. Such misplacement of tetrad-forming guanines in a loop is also seen in other structures such as 2a5r, 2kpr, 2m53, 2m92, etc (Supplementary Table 2).
The G4 module in DSSR was first developed around 2017-2018 and the work was mentioned briefly in the Lu (2020) paper on DSSR-PyMOL integration. However, due to the funding gap, the development of the G4 module was put on hold. I have never got a chance to write a paper documenting the detailed algorithms for the identification, annotation, and visualization of G-quadruplexes. I recently revamped the G4.x3dna.org website from inside out, and reprocessed all PDB structures to compile the DSSR-G4DB database. Along the way, the G4 module has been updated and improved. Now I'm actively working on a manuscript on the G4 module in DSSR and the associate website.
DSSR has clear definitions of G4-helix and G4-stem, and the corresponding loops. Specifically, for PDB entry 2a5p, DSSR reports the following:
## List of 1 G4-helix
In DSSR, a G4-helix is defined by stacking interactions of G-tetrads, regardless of backbone connectivity,
and may contain more than one G4-stem.
##### Helix#1, 3 G-tetrads, INTRA-molecular, with 1 stem
1 glyco-bond=---- sugar=---- groove=---- WC-->Major O+ nts=4 GGGG A.DG4,A.DG8,A.DG13,A.DG17
2 glyco-bond=---- sugar=.--- groove=---- WC-->Major O+ nts=4 GGGG A.DG5,A.DG9,A.DG14,A.DG18
3 glyco-bond=-s-- sugar=-3-- groove=wn-- WC-->Major Z- nts=4 GGGG A.DG6,A.DG24,A.DG15,A.DG19
step#1 pm(>>,forward) area=9.64 rise=3.19 twist=32.7
step#2 pm(>>,forward) area=12.93 rise=3.29 twist=29.4
strand#1 DNA glyco-bond=--- sugar=-.- nts=3 GGG A.DG4,A.DG5,A.DG6
strand#2 DNA glyco-bond=--s sugar=--3 nts=3 GGG A.DG8,A.DG9,A.DG24
strand#3 DNA glyco-bond=--- sugar=--- nts=3 GGG A.DG13,A.DG14,A.DG15
strand#4 DNA glyco-bond=--- sugar=--- nts=3 GGG A.DG17,A.DG18,A.DG19
Notice the differences in grooves between the first two G-tetrads vs the 3rd one, and the breaking backbone for strand#2 between G9 and G24.
## List of 1 G4-stem
In DSSR, a G4-stem is defined as a G4-helix with backbone connectivity.
Bulges are also allowed along each of the four strands.
##### Stem#1, 2 G-tetrads, 3 loops, INTRA-molecular, UUUU, parallel, 2(-P-P-P), parallel(4+0)
1 glyco-bond=---- sugar=---- groove=---- WC-->Major O+ nts=4 GGGG A.DG4,A.DG8,A.DG13,A.DG17
2 glyco-bond=---- sugar=.--- groove=---- WC-->Major O+ nts=4 GGGG A.DG5,A.DG9,A.DG14,A.DG18
step#1 pm(>>,forward) area=9.64 rise=3.19 twist=32.7
strand#1 U DNA glyco-bond=-- sugar=-. nts=2 GG A.DG4,A.DG5
strand#2 U DNA glyco-bond=-- sugar=-- nts=2 GG A.DG8,A.DG9
strand#3 U DNA glyco-bond=-- sugar=-- nts=2 GG A.DG13,A.DG14
strand#4 U DNA glyco-bond=-- sugar=-- nts=2 GG A.DG17,A.DG18
loop#1 type=propeller strands=[#1,#2] nts=2 GT A.DG6,A.DT7
loop#2 type=propeller strands=[#2,#3] nts=3 gGA A.DI10,A.DG11,A.DA12
loop#3 type=propeller strands=[#3,#4] nts=2 GT A.DG15,A.DT16
Thus the G4-stem consists of two G-tetrads only, and G6 which is part of the 3rd G-tetrad becomes part of a propeller loop. Similar arrangement applies to the other cases.
 DSSR also reports the following loop:
DSSR also reports the following loop:
## List of 1 non-stem G4-loop (including the two closing Gs)
1 type=diagonal helix=#1 nts=6 GGAAGG A.DG19,A.DG20,A.DA21,A.DA22,A.DG23,A.DG24
In my understanding, the definition and nomenclature of loops in G4 structures are not yet standardized. I am monitoring the development in this field and will update DSSR as needed in due course.
There may also be different types of loops identified by these tools. For example, in 1oz8, which is depicted by CIISGQ as two separate G4s, DSSR fails to identify the G-tetrad, [2, 5, 8, 11], that lies on the outside of the structure. This results in identification of loops formed within this tetrad and its stacking neighbor different to CIIS-GQ. While CIISGQ identifies these loops as reversal, just like the other loops in the structure, DSSR identifies them as non-stem lateral loops. This causes complete misinterpretation of the size and the type of loops in the structure.
The revised DSSR output for PDB entry 1oz8 has the G-tetrad A.DG2,A.DG5,A.DG8,A.DG11 manually added as part of the input, and now all three propeller loops are correctly identified. By default, G11 does not form proper G+G pairs (of LW type cWH or cHW, and Saenger type VI) with G2 and G8. The distortion of the G-tetrad is obvious in the block representation of the structure.
In 4u5m, similar to 1oz8, the structure may be interpreted as two separate G4s connected through a single link (T13,T14). In this case, DSSR identifies only two loops in one of the G4s and labels them as non-stem V-shaped loops. This also differs from CIIS-GQ where CIIS-GQ interprets all loops in both G4 as reversal. Structures containing multiple G4s, such as 1oz8, 4u5m and 6kvb, are often identified with different loop types by DSSR, while CIIS-GQ can recognise the loops correctly and simplifies the comprehension of the structure.
For PDB entry 4u5m, the same arguments above regarding the G4-stem and loops for 2a5p apply.
1 glyco-bond=s--- sugar=---- groove=w--n Major-->WC O+ nts=4 GGGG A.DG2,A.DG11,A.DG8,A.DG5
2 glyco-bond=---- sugar=---- groove=---- Major-->WC O+ nts=4 GGGG A.DG3,A.DG12,A.DG9,A.DG6
3 glyco-bond=---- sugar=---- groove=---- WC-->Major O+ nts=4 GGGG A.DG24,A.DG15,A.DG18,A.DG21
4 glyco-bond=---- sugar=---- groove=---- WC-->Major O+ nts=4 GGGG A.DG23,A.DG26,A.DG17,A.DG20
As shown, the backbone between G15 and G26 is broken. Moreover, here the assignment of Gs along the strand may need to be manually adjusted.
As shown in Table 1, by relaxing angle and distance parameters, we were able to identify more tetrads (6T2G, 1OZ8) than DSSR, which detects them as multiplets instead.
The current DSSR results for PDB entry 6t2g and 1oz8 are all as expected. Moreover, DSSR can handle PDB entry 6t2g automatically, while for PDB entry 1oz8 user needs to manually edit the input to include the G-tetrad with G11. By allowing users to specify tetrads, DSSR offers precise control and great flexibility, e.g., to include the G-C-G-C tetrads in PDB entry 1a6h.
DSSR has a detailed explanation of strands, tetrads and loops. However, the comprehensive output of DSSR is often hard to understand and grasp the details of the structure. [in supplemental materials]
The detailed explanations are provided to help users understand the DSSR output. They are most insightful in combination with the schematic block diagrams. For examples, for PDB entry 1a6h, the middle G-C-G-C tetrads are crystal clear with the long green and yellow rectangular blocks, specially along with the detailed annotations of the tetrads, as shown below.
1 glyco-bond=s-s- sugar=---. groove=wnwn Major-->WC -- nts=4 GGGG A.DG1,A.DG11,B.DG8,B.DG4
2 glyco-bond=---- sugar=-.-- groove=---- -- -- nts=4 CGCG A.DC2,A.DG10,B.DC9,B.DG3
3 glyco-bond=---- sugar=--.- groove=---- -- -- nts=4 GCGC A.DG3,A.DC9,B.DG10,B.DC2
4 glyco-bond=-s-s sugar=---- groove=wnwn WC-->Major -- nts=4 GGGG A.DG4,A.DG8,B.DG11,B.DG1
Another advantage of CIIS-GQ is that it requires only two thresholds, the thresholds of distance and angle parameters that can be modified to detect loosely connected tetrads. Due to this advantage, the identification of the tetrads were possible in at least two structures. In case of 1OZ8, DSSR found three tetrads (G1-G4-G7-G10, G13-G16-G19-G22 and G14-G17-G20-G23) as shown at the result page2 (47) while CIIS-GQ has found one more tetrad which is G2-G5-G8-G11. In comparison DSSR highlighted G5-G8-G11 as a multiplet, omitting the G2. Based on this difference, loop classification differs with CIIS-GQ. DSSR has identified 3 stem reversal loops and 3 non-stem lateral loops while we have identified 7 reversal loops. Stem loop is defined as any loop that also forms a duplex within itself.
DSSR now has PDB entry 1oz8 properly characterized, by manually adding the G-tetrad involving G11, as detailed above.
A similar difference exists in 6T2G. DSSR could find 2 tetrads in this structure (G2-G6-G11-G26 and G4-G9-G13-G28) as shown at the result page3 (47) while CIIS-GQ found one more tetrad, G3-G7-G12-G27. DSSR is able to show these four guanines as a multiplet in the list of multiplets section, however does not present it as a tetrad like the other two tetrads. As a result, CIIS-GQ loop types and placements are also different. DSSR has found six lateral loops while CIIS-GQ has found three reversal loops.
DSSR can now handle PDB entry 6t2g automatically. Previous versions of DSSR missed the G-tetrad (G3+G7+G12+G27) because of the G12+G27 pair: it fails the criteria to be classified as the pair of LW type cWH or cHW and Saenger type VI. Thus G3+G7+G12+G27 do not qualify as a G-tetrad, but they still form a multiplet with four guanines.
References
Direk, T., & Doluca, O. (2024). Computational Identification and Illustrative Standard for Representation of Unimolecular G-Quadruplex Secondary Structures (CIIS-GQ). Journal of Computer-Aided Molecular Design, 38(1), 35. https://doi.org/10.1007/s10822-024-00573-1
Lu, X.-J. (2020). DSSR-enabled innovative schematics of 3D nucleic acid structures with PyMOL. Nucleic Acids Research, gkaa426. https://doi.org/10.1093/nar/gkaa426
By following citations to 3DNA/DSSR, I recently came across the paper "RNAtango: Analysing and comparing RNA 3D structures via torsional angles" in PLOS Computational Biology by Mackowiak M, Adamczyk B, Szachniuk M, and Zok T. This work provides a nice summary of definitions of torsion and pseudo-torsion angles in RNA structure, and an angular metrics (MCQ, Mean of Circular Quantities) to score structure similarity. The RNAtango web application allows user to explore the distribution of torsion angles in a single structure/fragment (Single model), compare RNA models with a native structure (Models vs Target), or perform a comparative analysis in a set of models (Model vs Model).
In the Introduction section, 3DNA/DSSR are mentioned along with other related tools, as below:
Several bioinformatics tools have been designed for analyzing torsion and pseudotorsion angles, each with its own strengths and limitations. 3DNA, an open-source toolkit, provides comprehensive functionality, including torsion and pseudotorsion angle calculations [27], but lacks support for the current standard PDBx/mmCIF file format. DSSR, the successor to 3DNA, overcomes this limitation by supporting both PDB and PDBx/mmCIF files. However, it is a closed-source, commercial application that requires licensing, even for research purposes [28]. Curves+, another tool used for torsion angle analysis, is currently inaccessible due to the unavailability of its webpage and source code hosting [29]. Barnaba, a Python library and toolset for analyzing single structures or trajectories, supports torsion angle calculations but, like 3DNA, does not support the PDBx/mmCIF format [30]. For users seeking a more user friendly option, AMIGOS III offers a PyMOL plugin that calculates pseudotorsion angles and presents them in Ramachandran-like plots [17].
Every bioinformatic software has been developed for a specific purpose, and no two such tools can be identical. It is a good thing that the community has a choice for RNA backbone analysis. Indeed, 3DNA has been superseded by DSSR, which is licensed by Columbia Technology Ventures (CTV) to ensure its continuous development and availability. However, DSSR remain competitive due to its unmatched functionality, usability, and support: it saves users a substantial amount of time and effort when compared to other options.
From the very beginning, it has been my dream to make DSSR stand out for its quality and value, and be widely accessible. The CTV DSSR distribution by no means follow typical commercial license for a software product: specifically, it does not include a license key to limit DSSR's usage to a specific machine and operating system, and there is no expire date for the software either. Moreover, the Basic Academic license was free of charge when DSSR was initially licensed by the CTV in August 2020, and remained so until around end of 2021 when the web-based "Express Licenses" functionality no longer worked. Manually handling the large number of requests for free academic licenses was not sustainable, and that was when the DSSR Basic Academic free license was removed. Upon user requests, we late on re-introduced DSSR Basic Academic license, but with a one-time fee of $200 to cover the running cost. That may be reason for the remark in the RNAtango paper that DSSR "requires licensing, even for research purposes".
With the recent NIH R24 funding support on "X3DNA-DSSR: a resource for structural bioinformatics of nucleic acids", we are providing DSSR Basic free of charge to the academic community. Academic Users may submit a license request for DSSR Basic or DSSR Pro by clicking "Express Licensing". Checking the list of licensees, I am thrilled to see the many new DSSR users from leading institutions around the world, including Stockholm University, Ghent University, Universitaet Heidelberg, University of Palermo, CSSB-Hamburg, Nicolaus Copernicus University, NIH, Harvard, ... Clearly, DSSR fills a niche, and the demands for it remain strong!
Back to torsion angles, it is safe to say that DSSR has unique features not available or easily accessible elsewhere. Here are some use cases using tRNA PDB entry 1ehz as an example:
x3dna-dssr -i=1ehz.cif # generate dssr-torsions.txt among other output files
x3dna-dssr -i=1ehz.cif --torsion-file -o=1ehz-torsions.txt # just the torsion file 1ehz-torsions.txt
x3dna-dssr -i=1ehz.cif --json | jq .nts[54] > 1ehz-PSU55.txt # DSSR-derived features for nucleotide PSU55
Users can easily run the DSSR commands listed above and get the results in human-readable text and machine-friendly JSON formats. For verification, the contents of 1ehz-torsions.txt and 1ehz-PSU55.txt are available by clicking the links.
It is worth noting that DSSR has the --nmr option for the analysis of an ensemble of NMR structures, in .pdb or .cif format, as deposited in the PDB. The combination of --nmr and --json renders DSSR easily accessible to the molecular dynamics (MD) community.
In principle, calculating torsion angles is a straightforward process. In reality, factors such as modified nucleotides (especially pseudouridine), missing atoms, NMR ensembles or MD trajectories, PDB vs mmCIF formats, etc. make the implementation complicated. Without paying great attention to details, it is easy to make subtle mistakes. For example, with RNAtango the chi (χ) torsion angle for A.PSU55 of 1ehz is listed as -152.42°, which is wrong. The correct value should be -147.0° as reported by DSSR (see below and the link 1ehz-PSU55.txt above).
DSSR provides a comprehensive list of backbone parameters (as listed below for 1ehz). The program is efficient and robust, and has been battle tested. I am always quick to fix any bugs once verified, and am willing to add new features once thoroughly studied. In short, DSSR has been designed to be a reliable tool that the community can trust and build upon.
DSSR-derived backbone features for tRNA 1ehz:
Output of DNA/RNA backbone conformational parameters
DSSR v2.4.5-2024sep24 by xiangjun@x3dna.org
******************************************************************************************
Main chain conformational parameters:
alpha: O3'(i-1)-P-O5'-C5'
beta: P-O5'-C5'-C4'
gamma: O5'-C5'-C4'-C3'
delta: C5'-C4'-C3'-O3'
epsilon: C4'-C3'-O3'-P(i+1)
zeta: C3'-O3'-P(i+1)-O5'(i+1)
e-z: epsilon-zeta (BI/BII backbone classification)
chi for pyrimidines(Y): O4'-C1'-N1-C2; purines(R): O4'-C1'-N9-C4
Range [170, -50(310)] is assigned to anti, and [50, 90] to syn
phase-angle: the phase angle of pseudorotation and puckering
sugar-type: ~C2'-endo for C2'-endo like conformation, or
~C3'-endo for C3'-endo like conformation
Note the ONE column offset (for easy visual distinction)
ssZp: single-stranded Zp, defined as the z-coordinate of the 3' phosphorus atom
(P) expressed in the standard reference frame of the 5' base; the value is
POSITIVE when P lies on the +z-axis side (base in anti conformation);
NEGATIVE if P is on the -z-axis side (base in syn conformation)
Dp: perpendicular distance of the 3' P atom to the glycosidic bond
[Ref: Chen et al. (2010): "MolProbity: all-atom structure
validation for macromolecular crystallography."
Acta Crystallogr D Biol Crystallogr, 66(1):12-21]
splay: angle between the bridging P to the two base-origins of a dinucleotide.
nt alpha beta gamma delta epsilon zeta e-z chi phase-angle sugar-type ssZp Dp splay
1 G A.G1 --- -128.1 67.8 82.9 -155.6 -68.6 -87(BI) -167.8(anti) 16.1(C3'-endo) ~C3'-endo 4.59 4.57 24.92
2 C A.C2 -67.4 -178.4 53.8 83.4 -145.1 -76.8 -68(BI) -163.8(anti) 16.1(C3'-endo) ~C3'-endo 4.52 4.63 21.15
3 G A.G3 -74.5 169.7 59.5 80.7 -148.3 -80.0 -68(BI) -161.9(anti) 14.6(C3'-endo) ~C3'-endo 4.75 4.69 22.28
4 G A.G4 -64.4 162.2 60.7 82.2 -157.4 -68.7 -89(BI) -168.7(anti) 20.8(C3'-endo) ~C3'-endo 4.68 4.57 25.22
5 A A.A5 -74.7 -176.5 53.4 84.9 -137.5 -81.7 -56(BI) -162.9(anti) 4.8(C3'-endo) ~C3'-endo 4.49 4.76 22.04
6 U A.U6 -48.8 157.6 55.3 81.3 -151.0 -77.0 -74(BI) -160.0(anti) 18.2(C3'-endo) ~C3'-endo 4.31 4.51 22.89
7 U A.U7 -59.5 -178.7 62.5 137.3 -105.9 -52.0 -54(--) -133.1(anti) 156.1(C2'-endo) ~C2'-endo 1.55 1.41 126.99
8 U A.U8 -83.8 -145.6 55.4 78.6 -142.8 -118.6 -24(--) -161.5(anti) 10.5(C3'-endo) ~C3'-endo 4.60 4.76 62.37
9 A A.A9 -69.7 -141.7 52.3 147.8 -106.2 -77.3 -29(--) -70.5(anti) 149.8(C2'-endo) ~C2'-endo 1.00 1.14 57.38
10 g A.2MG10 177.8 147.2 60.1 89.3 -126.2 -88.7 -37(--) 169.6(anti) 6.6(C3'-endo) ~C3'-endo 4.68 4.63 23.87
11 C A.C11 -56.1 167.9 48.2 87.2 -150.5 -69.9 -81(BI) -160.9(anti) 16.8(C3'-endo) ~C3'-endo 4.28 4.46 21.20
12 U A.U12 -67.8 172.9 51.8 80.7 -158.5 -65.2 -93(BI) -158.3(anti) 25.2(C3'-endo) ~C3'-endo 4.29 4.45 21.01
13 C A.C13 166.6 -169.9 178.6 82.5 -153.1 -97.4 -56(BI) -168.3(anti) 23.7(C3'-endo) ~C3'-endo 4.28 4.36 31.59
14 A A.A14 83.4 -158.3 -114.6 92.0 -125.5 -57.3 -68(--) -170.7(anti) 358.9(C2'-exo) ~C3'-endo 4.67 4.74 38.01
15 G A.G15 -55.1 162.5 51.9 79.8 -136.3 -143.9 8(--) -164.5(anti) 16.0(C3'-endo) ~C3'-endo 4.72 4.74 26.17
16 u A.H2U16 -6.1 91.2 76.8 96.8 -61.8 -131.2 69(--) -85.8(anti) 18.8(C3'-endo) ~C3'-endo -0.71 3.38 145.77
17 u A.H2U17 27.8 107.7 174.1 94.8 178.0 76.2 102(--) -142.5(anti) 341.4(C2'-exo) ~C3'-endo -0.90 4.20 105.55
18 G A.G18 45.4 -159.4 59.0 150.6 -95.2 -179.1 84(BII) -99.5(anti) 154.3(C2'-endo) ~C2'-endo 1.60 1.09 51.64
19 G A.G19 -71.4 -178.9 53.8 153.8 -91.6 -83.7 -8(--) -80.3(anti) 167.6(C2'-endo) ~C2'-endo -1.14 0.48 130.30
20 G A.G20 -81.3 -150.7 47.8 89.9 -122.3 -54.1 -68(--) 177.8(anti) 8.7(C3'-endo) ~C3'-endo 4.90 4.76 57.04
21 A A.A21 -75.6 148.6 -176.6 78.2 -168.9 -75.6 -93(BI) -160.2(anti) 13.0(C3'-endo) ~C3'-endo 4.00 4.26 40.66
22 G A.G22 158.8 153.5 179.3 82.0 -145.0 -80.4 -65(BI) -175.5(anti) 353.8(C2'-exo) ~C3'-endo 4.60 4.73 25.62
23 A A.A23 -53.3 174.8 52.5 82.3 -155.3 -66.4 -89(BI) -158.0(anti) 12.6(C3'-endo) ~C3'-endo 4.18 4.61 22.96
24 G A.G24 -68.8 178.2 46.8 83.6 -144.3 -72.8 -71(BI) -160.7(anti) 13.4(C3'-endo) ~C3'-endo 4.63 4.74 20.51
25 C A.C25 -65.1 168.9 53.9 83.3 -145.1 -68.4 -77(BI) -160.3(anti) 17.4(C3'-endo) ~C3'-endo 4.56 4.70 30.70
26 g A.M2G26 -53.8 170.8 47.7 86.0 -136.3 -76.9 -59(BI) -163.4(anti) 9.3(C3'-endo) ~C3'-endo 4.57 4.67 27.36
27 C A.C27 -53.0 166.9 43.6 83.4 -148.5 -73.4 -75(BI) -168.2(anti) 18.3(C3'-endo) ~C3'-endo 4.53 4.62 23.07
28 C A.C28 -72.4 178.3 49.3 80.1 -152.1 -67.0 -85(BI) -160.6(anti) 9.2(C3'-endo) ~C3'-endo 4.55 4.73 21.61
29 A A.A29 -66.6 174.0 55.6 81.4 -155.5 -78.3 -77(BI) -165.9(anti) 13.7(C3'-endo) ~C3'-endo 4.73 4.65 26.96
30 G A.G30 -54.0 165.9 56.9 83.6 -144.7 -62.3 -82(BI) -171.7(anti) 14.5(C3'-endo) ~C3'-endo 4.67 4.65 25.72
31 A A.A31 -69.9 177.8 52.3 83.7 -137.0 -75.5 -61(BI) -156.7(anti) 14.6(C3'-endo) ~C3'-endo 4.24 4.72 21.52
32 c A.OMC32 -52.7 161.4 49.3 80.1 -145.9 -71.2 -75(BI) -149.9(anti) 20.4(C3'-endo) ~C3'-endo 4.16 4.63 25.94
33 U A.U33 -67.7 -177.0 47.0 82.1 -148.0 -53.7 -94(BI) -148.2(anti) 13.3(C3'-endo) ~C3'-endo 4.19 4.64 75.47
34 g A.OMG34 171.1 148.1 52.5 83.4 -132.5 -71.8 -61(BI) -171.2(anti) 12.2(C3'-endo) ~C3'-endo 4.15 4.58 22.09
35 A A.A35 -47.7 163.7 40.2 80.9 -143.7 -59.5 -84(BI) -154.4(anti) 21.9(C3'-endo) ~C3'-endo 4.20 4.54 20.57
36 A A.A36 -52.4 165.7 51.3 72.2 -160.4 -85.2 -75(BI) -158.4(anti) 45.8(C4'-exo) ~C3'-endo 4.49 4.31 24.48
37 g A.YYG37 -57.5 163.0 47.8 81.1 -148.1 -67.0 -81(BI) -168.8(anti) 15.4(C3'-endo) ~C3'-endo 4.63 4.65 32.08
38 A A.A38 -61.8 -180.0 46.9 82.5 -136.8 -76.4 -60(BI) -169.4(anti) 2.4(C3'-endo) ~C3'-endo 4.63 4.78 23.75
39 P A.PSU39 -47.7 160.4 53.3 79.3 -140.1 -68.6 -72(BI) -165.6(anti) 15.8(C3'-endo) ~C3'-endo 4.55 4.68 26.68
40 c A.5MC40 -67.4 172.0 56.2 83.2 -154.2 -74.9 -79(BI) -162.6(anti) 17.3(C3'-endo) ~C3'-endo 4.52 4.60 27.71
41 U A.U41 -68.2 -179.4 52.4 78.9 -137.3 -84.7 -53(BI) -169.0(anti) 13.4(C3'-endo) ~C3'-endo 4.54 4.75 24.14
42 G A.G42 -47.9 158.7 55.6 79.8 -160.3 -70.3 -90(BI) -169.0(anti) 20.9(C3'-endo) ~C3'-endo 4.43 4.51 23.54
43 G A.G43 -67.0 -178.3 55.6 81.6 -154.9 -76.4 -78(BI) -160.2(anti) 12.6(C3'-endo) ~C3'-endo 4.24 4.61 20.95
44 A A.A44 -59.7 162.1 60.0 85.3 -142.8 -57.2 -86(BI) -159.4(anti) 16.9(C3'-endo) ~C3'-endo 4.25 4.61 31.07
45 G A.G45 -71.9 -176.9 51.0 87.6 -135.1 -78.7 -56(BI) -149.3(anti) 15.4(C3'-endo) ~C3'-endo 4.01 4.58 40.27
46 g A.7MG46 -56.8 -146.5 48.4 141.6 -102.7 -137.9 35(--) -65.8(anti) 154.5(C2'-endo) ~C2'-endo 0.21 0.96 139.04
47 U A.U47 62.4 -164.0 44.4 146.1 -93.7 -78.0 -16(--) -112.0(anti) 164.9(C2'-endo) ~C2'-endo 0.26 0.39 157.37
48 C A.C48 -73.5 -174.3 161.5 145.6 -143.5 75.6 141(--) -140.1(anti) 158.2(C2'-endo) ~C2'-endo 1.92 1.80 147.54
49 c A.5MC49 50.7 168.5 42.2 84.3 -145.0 -82.1 -63(BI) -173.6(anti) 10.1(C3'-endo) ~C3'-endo 4.77 4.75 25.83
50 U A.U50 -51.7 177.2 42.1 80.4 -150.6 -67.8 -83(BI) -165.3(anti) 5.6(C3'-endo) ~C3'-endo 4.38 4.75 23.15
51 G A.G51 -63.9 176.8 52.8 79.4 -150.4 -71.3 -79(BI) -156.6(anti) 11.5(C3'-endo) ~C3'-endo 4.44 4.67 21.28
52 U A.U52 -64.7 173.6 48.5 80.3 -156.5 -69.4 -87(BI) -164.0(anti) 14.1(C3'-endo) ~C3'-endo 4.64 4.74 25.47
53 G A.G53 -56.9 171.5 56.2 83.9 -159.4 -64.9 -95(BI) -169.2(anti) 19.8(C3'-endo) ~C3'-endo 4.59 4.57 24.53
54 t A.5MU54 -79.7 -172.8 57.7 77.6 -128.6 -70.7 -58(BI) -161.5(anti) 20.6(C3'-endo) ~C3'-endo 4.56 4.80 30.73
55 P A.PSU55 -49.7 168.8 44.1 76.6 -140.8 -69.9 -71(BI) -147.0(anti) 10.1(C3'-endo) ~C3'-endo 4.15 4.74 71.28
56 C A.C56 166.4 171.8 53.3 83.4 -132.7 -70.6 -62(BI) -161.5(anti) 12.6(C3'-endo) ~C3'-endo 4.37 4.76 28.07
57 G A.G57 -65.7 167.1 57.5 81.7 -145.2 -67.6 -78(BI) -159.3(anti) 12.8(C3'-endo) ~C3'-endo 4.36 4.65 42.47
58 a A.1MA58 -60.8 -146.1 71.8 156.7 -78.3 -169.3 91(BII) -86.3(anti) 161.1(C2'-endo) ~C2'-endo 0.48 0.68 73.92
59 U A.U59 72.6 -158.8 63.7 84.6 -148.8 -53.7 -95(BI) -165.6(anti) 25.8(C3'-endo) ~C3'-endo 4.67 4.42 27.88
60 C A.C60 -72.2 179.5 66.0 148.3 -97.1 -66.4 -31(--) -117.8(anti) 154.8(C2'-endo) ~C2'-endo 0.99 0.86 90.64
61 C A.C61 -84.3 179.8 38.2 83.0 -152.3 -74.5 -78(BI) -166.7(anti) 14.8(C3'-endo) ~C3'-endo 4.45 4.52 25.80
62 A A.A62 -60.1 179.6 46.9 80.5 -145.6 -74.1 -71(BI) -158.7(anti) 9.9(C3'-endo) ~C3'-endo 4.18 4.66 19.23
63 C A.C63 -62.0 167.3 50.9 80.7 -152.3 -70.7 -82(BI) -152.6(anti) 10.7(C3'-endo) ~C3'-endo 4.32 4.62 23.62
64 A A.A64 -66.9 180.0 44.1 75.8 -147.5 -76.5 -71(BI) -161.8(anti) 12.9(C3'-endo) ~C3'-endo 4.68 4.86 25.64
65 G A.G65 -44.0 164.2 49.9 79.8 -152.0 -73.3 -79(BI) -172.8(anti) 16.5(C3'-endo) ~C3'-endo 4.92 4.76 25.20
66 A A.A66 -57.9 178.5 52.0 81.7 -151.0 -73.5 -77(BI) -164.9(anti) 22.5(C3'-endo) ~C3'-endo 4.56 4.60 22.73
67 A A.A67 -62.0 164.1 54.2 83.2 -152.2 -78.3 -74(BI) -162.8(anti) 15.0(C3'-endo) ~C3'-endo 4.71 4.67 23.30
68 U A.U68 -59.8 175.3 47.3 82.2 -152.9 -65.4 -88(BI) -160.1(anti) 11.2(C3'-endo) ~C3'-endo 4.30 4.60 24.35
69 U A.U69 -63.8 168.1 55.1 79.1 -155.4 -85.6 -70(BI) -161.4(anti) 14.7(C3'-endo) ~C3'-endo 4.55 4.61 19.23
70 C A.C70 -61.7 164.6 53.1 79.0 -158.5 -64.5 -94(BI) -152.0(anti) 15.0(C3'-endo) ~C3'-endo 4.20 4.56 20.96
71 G A.G71 -78.4 173.6 60.3 80.3 -149.6 -68.4 -81(BI) -162.8(anti) 13.5(C3'-endo) ~C3'-endo 4.50 4.71 22.80
72 C A.C72 -73.2 176.2 62.1 83.0 -152.3 -67.9 -84(BI) -161.6(anti) 19.5(C3'-endo) ~C3'-endo 4.56 4.63 26.14
73 A A.A73 -63.3 177.7 50.4 81.6 -148.2 -66.1 -82(BI) -167.4(anti) 15.0(C3'-endo) ~C3'-endo 4.65 4.71 26.33
74 C A.C74 -66.9 -174.9 50.7 85.9 -145.0 -58.8 -86(BI) -153.1(anti) 11.8(C3'-endo) ~C3'-endo 4.22 4.61 33.45
75 C A.C75 -52.3 175.7 42.3 85.6 -131.9 163.9 64(BII) -151.7(anti) 15.1(C3'-endo) ~C3'-endo 3.96 4.60 159.78
76 A A.A76 -71.0 130.2 164.6 160.9 --- --- --- 138.5(anti) 176.1(C2'-endo) ~C2'-endo --- --- ---
******************************************************************************************
Virtual eta/theta torsion angles:
eta: C4'(i-1)-P(i)-C4'(i)-P(i+1)
theta: P(i)-C4'(i)-P(i+1)-C4'(i+1)
[Ref: Olson (1980): "Configurational statistics of polynucleotide chains.
An updated virtual bond model to treat effects of base stacking."
Macromolecules, 13(3):721-728]
eta': C1'(i-1)-P(i)-C1'(i)-P(i+1)
theta': P(i)-C1'(i)-P(i+1)-C1'(i+1)
[Ref: Keating et al. (2011): "A new way to see RNA." Quarterly Reviews
of Biophysics, 44(4):433-466]
eta": base(i-1)-P(i)-base(i)-P(i+1)
theta": P(i)-base(i)-P(i+1)-base(i+1)
nt eta theta eta' theta' eta" theta"
1 G A.G1 --- -139.3 --- -136.5 --- -110.8
2 C A.C2 171.9 -144.6 -175.5 -144.1 -136.1 -118.1
3 G A.G3 160.2 -151.4 173.9 -153.9 -145.0 -143.7
4 G A.G4 164.3 -144.6 177.7 -144.1 -154.8 -98.7
5 A A.A5 166.9 -138.1 -178.3 -135.8 -116.3 -111.6
6 U A.U6 172.1 -149.7 -170.8 -143.9 -130.1 -126.5
7 U A.U7 -158.0 -42.7 -138.7 -60.7 -120.5 -31.5
8 U A.U8 162.7 160.7 -159.9 -163.8 -142.6 176.2
9 A A.A9 -140.6 -38.9 -159.3 -112.7 157.1 -105.5
10 g A.2MG10 27.8 -130.3 97.2 -130.1 134.8 -110.3
11 C A.C11 170.3 -135.8 -175.7 -136.7 -137.8 -119.9
12 U A.U12 159.9 -121.6 176.5 -130.6 -148.5 -101.4
13 C A.C13 178.1 -179.1 -166.8 176.7 -118.5 178.4
14 A A.A14 171.9 -146.5 172.1 -133.4 -179.7 -74.6
15 G A.G15 164.3 -177.9 -166.6 -161.0 -92.6 -101.8
16 u A.H2U16 -124.1 -77.5 -114.2 -108.3 -72.5 -127.0
17 u A.H2U17 -10.5 -64.3 7.7 -94.7 17.3 -125.4
18 G A.G18 -21.0 -167.4 45.3 -160.9 61.3 -124.2
19 G A.G19 -127.4 -43.3 -122.0 -72.9 -105.8 -7.8
20 G A.G20 165.3 -100.4 -160.4 -101.1 -177.9 -115.4
21 A A.A21 -78.3 152.7 -68.0 155.1 -61.1 154.8
22 G A.G22 159.5 167.6 156.6 178.8 157.1 -162.6
23 A A.A23 178.4 -141.8 -173.5 -141.2 -156.1 -112.0
24 G A.G24 163.7 -139.5 177.7 -137.6 -137.6 -103.8
25 C A.C25 161.4 -132.6 179.2 -131.0 -128.2 -89.0
26 g A.M2G26 173.0 -133.0 -167.7 -130.4 -106.9 -93.6
27 C A.C27 163.5 -142.3 -178.0 -141.5 -123.6 -105.6
28 C A.C28 157.5 -143.8 171.1 -144.3 -136.3 -125.5
29 A A.A29 163.5 -152.9 179.0 -150.8 -142.9 -124.7
30 G A.G30 178.3 -127.8 -167.7 -126.5 -128.2 -72.5
31 A A.A31 165.4 -133.9 -174.3 -131.0 -101.0 -93.9
32 c A.OMC32 164.5 -139.2 -175.9 -138.0 -122.3 -108.9
33 U A.U33 165.1 -114.0 177.8 -158.5 -141.1 138.3
34 g A.OMG34 27.3 -121.7 50.5 -123.7 22.7 -84.4
35 A A.A35 162.5 -127.7 -177.7 -128.5 -116.8 -113.4
36 A A.A36 164.9 -172.7 -174.4 -169.2 -142.3 -115.1
37 g A.YYG37 163.1 -135.2 174.1 -131.3 -119.8 -79.8
38 A A.A38 170.2 -133.9 -173.3 -129.0 -104.3 -105.5
39 P A.PSU39 174.0 -132.6 -168.6 -131.2 -127.5 -89.6
40 c A.5MC40 163.1 -148.5 -177.6 -149.3 -115.9 -131.7
41 U A.U41 169.4 -148.8 177.2 -144.0 -152.9 -120.5
42 G A.G42 171.2 -150.4 -171.5 -151.6 -133.9 -124.5
43 G A.G43 174.2 -151.6 -174.4 -150.0 -134.0 -124.5
44 A A.A44 173.2 -120.4 -171.8 -120.0 -133.3 -72.6
45 G A.G45 168.6 -141.6 -168.3 -128.4 -103.4 -133.4
46 g A.7MG46 -143.2 -107.3 -133.6 -149.6 -148.2 -162.7
47 U A.U47 -31.5 -56.8 4.8 -91.0 24.9 -110.7
48 C A.C48 -82.5 53.9 -29.3 17.5 1.5 -107.6
49 c A.5MC49 -56.7 -145.3 -36.6 -142.8 103.2 -130.2
50 U A.U50 174.8 -146.6 -176.9 -142.8 -153.6 -113.8
51 G A.G51 170.3 -147.3 -175.5 -148.2 -134.2 -122.1
52 U A.U52 160.3 -145.8 173.9 -144.3 -141.8 -119.6
53 G A.G53 174.9 -141.5 -167.2 -142.4 -124.7 -111.6
54 t A.5MU54 171.1 -129.2 -177.4 -122.6 -133.3 -76.4
55 P A.PSU55 165.3 -115.2 -173.6 -155.4 -112.1 145.1
56 C A.C56 31.4 -126.9 51.6 -124.1 25.3 -87.4
57 G A.G57 164.3 -142.5 -174.1 -131.9 -119.2 -113.8
58 a A.1MA58 -131.5 -108.7 -105.3 -171.2 -104.2 159.8
59 U A.U59 1.8 -119.4 26.8 -109.9 49.0 -56.9
60 C A.C60 -171.8 -40.7 -130.1 -68.5 -70.2 -35.8
61 C A.C61 122.4 -148.3 168.6 -144.1 -158.2 -117.4
62 A A.A62 173.0 -146.6 -176.9 -144.9 -142.0 -119.6
63 C A.C63 164.5 -148.3 177.9 -149.6 -143.9 -128.6
64 A A.A64 158.4 -151.0 168.5 -148.2 -154.8 -122.8
65 G A.G65 173.6 -147.3 -172.0 -145.4 -130.5 -121.2
66 A A.A66 177.6 -145.4 -170.1 -142.7 -133.5 -111.9
67 A A.A67 165.6 -149.3 -176.9 -149.8 -129.8 -126.7
68 U A.U68 168.9 -138.2 179.4 -136.1 -143.2 -96.5
69 U A.U69 165.6 -160.5 -176.0 -161.2 -118.8 -156.9
70 C A.C70 166.7 -146.2 173.6 -149.0 -171.6 -127.0
71 G A.G71 161.0 -143.0 174.0 -142.3 -146.3 -113.4
72 C A.C72 166.1 -141.5 -177.5 -141.9 -131.5 -110.2
73 A A.A73 167.6 -137.8 -177.2 -133.3 -127.1 -89.8
74 C A.C74 171.2 -122.1 -172.8 -116.5 -116.2 -72.1
75 C A.C75 174.9 106.5 -161.9 109.8 -102.9 -139.3
76 A A.A76 --- --- --- --- --- ---
******************************************************************************************
Sugar conformational parameters:
v0: C4'-O4'-C1'-C2'
v1: O4'-C1'-C2'-C3'
v2: C1'-C2'-C3'-C4'
v3: C2'-C3'-C4'-O4'
v4: C3'-C4'-O4'-C1'
tm: the amplitude of pucker
P: the phase angle of pseudorotation
[Ref: Altona & Sundaralingam (1972): "Conformational analysis
of the sugar ring in nucleosides and nucleotides. A new
description using the concept of pseudorotation."
J Am Chem Soc, 94(23):8205-8212]
nt v0 v1 v2 v3 v4 tm P Puckering
1 G A.G1 1.7 -23.4 35.1 -35.2 21.1 36.5 16.1 C3'-endo
2 C A.C2 1.6 -23.2 34.8 -34.8 20.9 36.2 16.1 C3'-endo
3 G A.G3 2.7 -25.1 36.8 -36.1 21.2 38.1 14.6 C3'-endo
4 G A.G4 -1.6 -22.3 36.3 -38.2 25.0 38.8 20.8 C3'-endo
5 A A.A5 10.1 -32.6 41.5 -36.6 16.7 41.7 4.8 C3'-endo
6 U A.U6 0.3 -24.0 37.3 -38.1 23.9 39.2 18.2 C3'-endo
7 U A.U7 -24.4 35.4 -32.4 18.9 3.3 35.4 156.1 C2'-endo
8 U A.U8 5.8 -28.7 39.7 -37.2 19.7 40.4 10.5 C3'-endo
9 A A.A9 -31.7 41.8 -35.6 18.1 8.4 41.2 149.8 C2'-endo
10 g A.2MG10 7.8 -28.0 36.7 -33.0 15.9 37.0 6.6 C3'-endo
11 C A.C11 1.2 -21.2 32.1 -32.5 19.8 33.5 16.8 C3'-endo
12 U A.U12 -4.6 -19.3 34.5 -37.9 26.7 38.1 25.2 C3'-endo
13 C A.C13 -3.4 -19.4 33.8 -36.4 25.1 36.9 23.7 C3'-endo
14 A A.A14 12.6 -30.8 36.8 -30.2 11.0 36.8 358.9 C2'-exo
15 G A.G15 1.9 -24.6 36.8 -36.8 22.2 38.3 16.0 C3'-endo
16 u A.H2U16 0.0 -18.7 29.2 -30.2 19.2 30.9 18.8 C3'-endo
17 u A.H2U17 23.0 -36.7 35.1 -23.2 0.2 37.0 341.4 C2'-exo
18 G A.G18 -27.9 39.5 -35.0 20.2 4.8 38.9 154.3 C2'-endo
19 G A.G19 -17.6 31.0 -31.9 23.1 -3.8 32.7 167.6 C2'-endo
20 G A.G20 6.6 -27.8 36.6 -34.2 17.5 37.0 8.7 C3'-endo
21 A A.A21 3.8 -25.0 35.1 -34.4 19.4 36.0 13.0 C3'-endo
22 G A.G22 16.4 -34.1 38.1 -29.5 8.3 38.3 353.8 C2'-exo
23 A A.A23 4.2 -26.6 37.4 -36.5 20.1 38.3 12.6 C3'-endo
24 G A.G24 3.9 -28.4 40.3 -39.3 22.4 41.5 13.4 C3'-endo
25 C A.C25 0.6 -24.5 37.8 -38.0 23.6 39.6 17.4 C3'-endo
26 g A.M2G26 6.3 -27.5 37.1 -34.7 17.9 37.6 9.3 C3'-endo
27 C A.C27 0.2 -23.5 36.5 -37.2 23.6 38.4 18.3 C3'-endo
28 C A.C28 6.6 -29.0 39.1 -36.3 18.8 39.6 9.2 C3'-endo
29 A A.A29 3.4 -26.6 38.4 -37.4 21.4 39.5 13.7 C3'-endo
30 G A.G30 2.6 -24.2 35.7 -34.9 20.4 36.9 14.5 C3'-endo
31 A A.A31 2.6 -24.0 35.0 -34.6 20.2 36.2 14.6 C3'-endo
32 c A.OMC32 -1.2 -21.7 35.1 -36.7 23.9 37.4 20.4 C3'-endo
33 U A.U33 3.5 -25.4 36.5 -35.3 20.1 37.5 13.3 C3'-endo
34 g A.OMG34 3.9 -22.7 32.2 -30.8 17.1 32.9 12.2 C3'-endo
35 A A.A35 -2.0 -19.9 32.7 -34.9 23.4 35.2 21.9 C3'-endo
36 A A.A36 -20.6 -7.3 30.6 -43.2 40.5 43.9 45.8 C4'-exo
37 g A.YYG37 2.1 -24.1 36.0 -35.6 21.0 37.4 15.4 C3'-endo
38 A A.A38 10.9 -30.3 37.6 -32.5 13.6 37.7 2.4 C3'-endo
39 P A.PSU39 2.1 -25.6 38.5 -38.4 22.8 40.0 15.8 C3'-endo
40 c A.5MC40 0.8 -22.5 34.6 -35.0 21.5 36.3 17.3 C3'-endo
41 U A.U41 3.8 -27.7 39.9 -38.6 22.0 41.0 13.4 C3'-endo
42 G A.G42 -1.7 -22.4 36.8 -38.6 25.4 39.4 20.9 C3'-endo
43 G A.G43 4.3 -27.6 39.1 -37.6 21.1 40.1 12.6 C3'-endo
44 A A.A44 1.0 -23.0 35.2 -35.4 21.6 36.8 16.9 C3'-endo
45 G A.G45 2.1 -24.3 35.7 -35.4 21.2 37.0 15.4 C3'-endo
46 g A.7MG46 -27.4 38.6 -34.7 19.7 4.7 38.5 154.5 C2'-endo
47 U A.U47 -20.9 34.8 -35.1 24.3 -2.2 36.4 164.9 C2'-endo
48 C A.C48 -25.6 38.4 -35.6 22.1 2.1 38.4 158.2 C2'-endo
49 c A.5MC49 5.8 -28.1 38.7 -36.0 19.1 39.3 10.1 C3'-endo
50 U A.U50 9.4 -32.2 41.0 -36.4 17.6 41.2 5.6 C3'-endo
51 G A.G51 4.9 -27.9 38.9 -36.8 20.3 39.7 11.5 C3'-endo
52 U A.U52 3.2 -28.5 41.4 -40.1 23.6 42.7 14.1 C3'-endo
53 G A.G53 -1.0 -23.1 37.0 -38.3 24.9 39.4 19.8 C3'-endo
54 t A.5MU54 -1.4 -22.2 35.9 -37.7 24.8 38.3 20.6 C3'-endo
55 P A.PSU55 6.2 -29.9 40.9 -38.3 20.4 41.5 10.1 C3'-endo
56 C A.C56 3.8 -25.3 35.7 -34.5 19.2 36.6 12.6 C3'-endo
57 G A.G57 4.0 -26.7 37.9 -36.5 20.6 38.9 12.8 C3'-endo
58 a A.1MA58 -24.3 38.4 -36.9 23.9 0.2 39.0 161.1 C2'-endo
59 U A.U59 -4.4 -18.3 31.8 -35.7 25.4 35.3 25.8 C3'-endo
60 C A.C60 -28.8 40.5 -36.4 21.2 4.7 40.3 154.8 C2'-endo
61 C A.C61 2.6 -25.5 36.8 -36.6 21.5 38.1 14.8 C3'-endo
62 A A.A62 5.9 -27.8 38.1 -35.4 18.8 38.7 9.9 C3'-endo
63 C A.C63 5.4 -27.3 37.5 -35.5 19.1 38.1 10.7 C3'-endo
64 A A.A64 4.1 -28.6 40.2 -38.8 22.2 41.2 12.9 C3'-endo
65 G A.G65 1.5 -26.6 39.5 -39.9 24.3 41.2 16.5 C3'-endo
66 A A.A66 -2.9 -21.6 36.5 -38.8 26.5 39.5 22.5 C3'-endo
67 A A.A67 2.4 -24.9 36.5 -36.1 21.4 37.8 15.0 C3'-endo
68 U A.U68 5.3 -28.4 39.5 -37.5 20.3 40.3 11.2 C3'-endo
69 U A.U69 2.9 -26.3 38.3 -37.9 22.3 39.6 14.7 C3'-endo
70 C A.C70 2.4 -25.9 38.7 -37.9 22.4 40.1 15.0 C3'-endo
71 G A.G71 3.7 -27.4 39.2 -38.3 21.8 40.3 13.5 C3'-endo
72 C A.C72 -0.6 -21.9 34.9 -36.2 23.1 37.0 19.5 C3'-endo
73 A A.A73 2.4 -25.4 37.3 -36.9 21.8 38.6 15.0 C3'-endo
74 C A.C74 4.4 -25.4 35.6 -34.0 18.6 36.4 11.8 C3'-endo
75 C A.C75 2.3 -22.5 33.1 -33.0 19.2 34.3 15.1 C3'-endo
76 A A.A76 -13.6 30.5 -34.8 27.7 -9.1 34.8 176.1 C2'-endo
******************************************************************************************
Assignment of sugar-phosphate backbone suites
bin: name of the 12 bins based on [delta(i-1), delta, gamma], where
delta(i-1) and delta can be either 3 (for C3'-endo sugar) or 2
(for C2'-endo) and gamma can be p/t/m (for gauche+/trans/gauche-
conformations, respectively) (2x2x3=12 combinations: 33p, 33t,
... 22m); 'inc' refers to incomplete cases (i.e., with missing
torsions), and 'trig' to triages (i.e., with torsion angle
outliers)
cluster: 2-char suite name, for one of 53 reported clusters (46
certain and 7 wannabes), '__' for incomplete cases, and
'!!' for outliers
suiteness: measure of conformer-match quality (low to high in range 0 to 1)
[Ref: Richardson et al. (2008): "RNA backbone: consensus all-angle
conformers and modular string nomenclature (an RNA Ontology
Consortium contribution)." RNA, 14(3):465-481]
nt bin cluster suiteness
1 G A.G1 inc __ 0
2 C A.C2 33p 1a 0.935
3 G A.G3 33p 1a 0.868
4 G A.G4 33p 1a 0.842
5 A A.A5 33p 1a 0.847
6 U A.U6 33p 1a 0.664
7 U A.U7 32p 1b 0.803
8 U A.U8 23p 2a 0.509
9 A A.A9 32p 1[ 0.046
10 g A.2MG10 23p 2g 0.640
11 C A.C11 33p 1a 0.507
12 U A.U12 33p 1a 0.898
13 C A.C13 33t 1c 0.824
14 A A.A14 trig !! 0
15 G A.G15 33p 1a 0.484
16 u A.H2U16 trig !! 0
17 u A.H2U17 33t !! 0
18 G A.G18 32p 5p 0.026
19 G A.G19 22p 4b 0.512
20 G A.G20 23p 2a 0.623
21 A A.A21 33t !! 0
22 G A.G22 33t 1f 0.714
23 A A.A23 33p 1a 0.840
24 G A.G24 33p 1a 0.881
25 C A.C25 33p 1a 0.967
26 g A.M2G26 33p 1a 0.819
27 C A.C27 33p 1a 0.698
28 C A.C28 33p 1a 0.923
29 A A.A29 33p 1a 0.973
30 G A.G30 33p 1a 0.838
31 A A.A31 33p 1a 0.914
32 c A.OMC32 33p 1a 0.782
33 U A.U33 33p 1a 0.897
34 g A.OMG34 33p 1g 0.784
35 A A.A35 33p 1a 0.517
36 A A.A36 33p 1a 0.670
37 g A.YYG37 33p 1a 0.625
38 A A.A38 33p 1a 0.903
39 P A.PSU39 33p 1a 0.680
40 c A.5MC40 33p 1a 0.942
41 U A.U41 33p 1a 0.945
42 G A.G42 33p 1a 0.630
43 G A.G43 33p 1a 0.882
44 A A.A44 33p 1a 0.837
45 G A.G45 33p 1a 0.749
46 g A.7MG46 32p 1[ 0.849
47 U A.U47 22p 4p 0.589
48 C A.C48 22t 2u 0.283
49 c A.5MC49 23p 6d 0.520
50 U A.U50 33p 1a 0.656
51 G A.G51 33p 1a 0.981
52 U A.U52 33p 1a 0.945
53 G A.G53 33p 1a 0.896
54 t A.5MU54 33p 1a 0.720
55 P A.PSU55 33p 1a 0.586
56 C A.C56 33p 1g 0.894
57 G A.G57 33p 1a 0.837
58 a A.1MA58 32p 1[ 0.332
59 U A.U59 23p 4d 0.411
60 C A.C60 32p 1b 0.662
61 C A.C61 23p 2a 0.553
62 A A.A62 33p 1a 0.895
63 C A.C63 33p 1a 0.964
64 A A.A64 33p 1a 0.791
65 G A.G65 33p 1a 0.586
66 A A.A66 33p 1a 0.940
67 A A.A67 33p 1a 0.941
68 U A.U68 33p 1a 0.891
69 U A.U69 33p 1a 0.951
70 C A.C70 33p 1a 0.809
71 G A.G71 33p 1a 0.761
72 C A.C72 33p 1a 0.832
73 A A.A73 33p 1a 0.965
74 C A.C74 33p 1a 0.886
75 C A.C75 33p 1a 0.639
76 A A.A76 32t !! 0
Concatenated suite string per chain. To avoid confusion of lower case
modified nucleotide name (e.g., 'a') with suite cluster (e.g., '1a'),
use --suite-delimiter to add delimiters (matched '()' by default).
1 A RNA nts=76 G1aC1aG1aG1aA1aU1bU2aU1[A2gg1aC1aU1cC!!A1aG!!u!!u5pG4bG2aG!!A1fG1aA1aG1aC1ag1aC1aC1aA1aG1aA1ac1aU1gg1aA1aA1ag1aA1aP1ac1aU1aG1aG1aA1aG1[g4pU2uC6dc1aU1aG1aU1aG1at1aP1gC1aG1[a4dU1bC2aC1aA1aC1aA1aG1aA1aA1aU1aU1aC1aG1aC1aA1aC1aC!!A
It gives me great pleasure to announce that the 3DNA/DSSR project is now funded by the NIH R24GM153869 grant, titled "X3DNA-DSSR: a resource for structural bioinformatics of nucleic acids". I am deeply grateful for the opportunity to continue working on a project that has basically defined who I am. It was a tough time during the funding gap over the past few years. Nevertheless, I have experienced and learned a lot, and witnessed miracles enabled by enthusiastic users.
Since late 2020 when I lost my R01 grant, DSSR has been licensed by the Columbia Technology Ventures (CTV). I appreciate the numerous users (including big pharma) who purchased a DSSR Pro License or a DSSR Basic paid License. Thanks to the NIH R24GM153869 grant, we are pleased to provide DSSR Basic free of charge to the academic community. Academic Users may submit a license request for DSSR Basic or DSSR Pro by clicking "Express Licensing" on the CTV landing page. Commercial users may inquire about pricing and licensing terms by emailing techtransfer@columbia.edu, copying xiangjun@x3dna.org.
DSSR v2.4.5-2024sep24 was released to synchronize with the new R24 funding, which will bring the project to an entirely new level. All existing users are encouraged to upgrade their installation to this release which contains miscellaneous bug fixes (e.g., chain id with > 4 chars) and numerous minor improvements.
Lots of exciting things will happen for the project. The first thing is to make DSSR freely accessible to the academic community. In the past couple of weeks, CTV have already issued quite a few DSSR Basic Academic licenses to users from all over the world. So the demand is high, and it will become stronger as more academic users become aware of DSSR. I'm closely monitoring the 3DNA Forum, and is always ready to answer users questions.
I am committed to making DSSR a brand that stands for quality and value. By virtue of its unmatched functionality, usability, and support, DSSR saves users a substantial amount of time and effort when compared to other options. My track record throughout the years has unambiguously demonstrated my dedication to this solid software product.
DSSR Basic contains all features described in the three DSSR-related papers, and includes the originally separate SNAP program (still unpublished) for analyzing DNA/RNA-protein complexes. The Pro version integrates the classic 3DNA functionality, plus advanced modeling routines, with email/Zoom/phone support.